OPENING30 秒开口版
Web3 数据变化很快,所以我会把 source priority、publishedAt、collectedAt、indexVersion、snapshot 和 conflictHint 都纳入证据链。结构化表给当前事实,RAG 给来源证明,score_snapshots 和 token_unlock_events 给时间序列。回答不仅给结论,还要说明数据更新时间、来源级别和是否有冲突。报告 Agent 生成周报时要冻结一个 data snapshot,引用同一个 runId 和数据版本,不能隔天自动漂移。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Freshness:数据或证据相对当前问题是否足够新。 Source Priority:多来源冲突时判断可信来源的优先级规则。 Snapshot:某个时间点冻结的数据视图,用于报告复现。 Index Version:RAG 或语义资产索引的版本,用于回放和缓存失效。 |
| 为什么这样回答 | 时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。 |
| 小白解析 | 同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。 |
| 关联知识点 | RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。 |
1 MIN一分钟口语版
具体架构上,采集层保留原始 source_documents、来源类型、内容 checksum、发布时间和采集时间;实体层做去重、消歧、冲突合并和 source priority;索引层按版本构建 RAG chunks 和 semantic assets;查询层锁定时间窗口、semanticVersion、indexVersion 和数据快照;交付层在 evidence 里展示 freshness、stale tags、conflictHint 和 source refs。比如融资金额官方公告和媒体报道不一致时,不让模型静默选一个,而是按优先级给主值、展示冲突并进入数据修复队列。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Freshness:数据或证据相对当前问题是否足够新。 Source Priority:多来源冲突时判断可信来源的优先级规则。 Snapshot:某个时间点冻结的数据视图,用于报告复现。 Index Version:RAG 或语义资产索引的版本,用于回放和缓存失效。 |
| 为什么这样回答 | 时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。 |
| 小白解析 | 同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。 |
| 关联知识点 | RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。 |
ARCHITECTURE架构设计要点
来源保留
source_documents 保存原文、来源、发布时间、采集时间和 checksum。
冲突合并
官方公告、链上数据、权威媒体、社区提交按 source priority 合并。
快照查询
报告 Agent 使用冻结数据快照,避免周报隔天漂移。
索引版本
RAG chunks、semantic assets、graph paths 都有 active version。
缓存失效
Token 解锁、行情、评分更新后刷新相关缓存和索引。
交付提示
answer 展示数据更新时间、stale tags、conflictHint 和风险。
DIAGRAM架构图
从多源采集到可引用证据
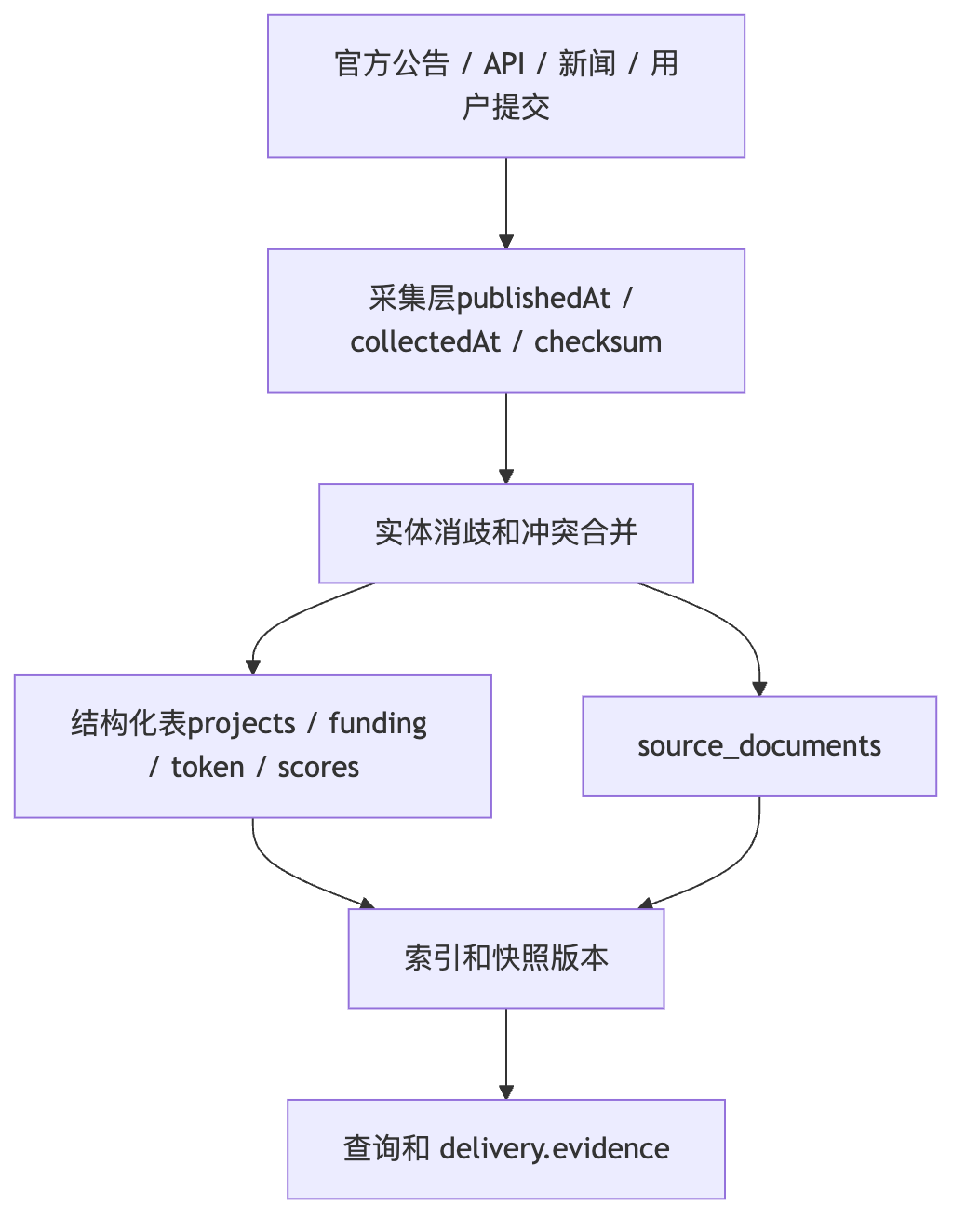
报告 Agent 如何冻结数据版本

TABLE关键对象和面试讲法
| 对象 | 职责 | 面试强调 |
|---|---|---|
| publishedAt | 来源发布时间 | 判断新闻和公告的新旧。 |
| collectedAt | 平台采集时间 | 判断采集延迟。 |
| contentChecksum | 内容指纹 | 识别来源内容变更。 |
| sourcePriority | 来源优先级 | 冲突时决定主值。 |
| snapshotTime | 快照时间 | 报告复现所需。 |
| indexVersion | 索引版本 | RAG 回放和缓存失效。 |
| conflictHint | 冲突说明 | 让用户知道多源不一致。 |
INTERVIEW MAP面试表达地图
- 先讲场景Web3 融资、解锁、行情、新闻变化快。
- 再讲对象source、时间、checksum、snapshot、indexVersion。
- 讲冲突多源不一致要优先级和显式提示。
- 讲复用报告 Agent 使用冻结版本。
- 讲风险过期、索引缺失、缓存陈旧要降级。
SUBAGENTS面试官、候选人和红队
本章写作前已实际启动多 subagent:面试官 subagent 负责连续追问生产压力,候选人 subagent 负责把答案压成现场能讲出口的表达,资料审阅 + 红队 subagent 负责指出哪些地方容易写虚,并补充安全、评测、runId、下游报告 Agent 的攻击面。
本章追问重点:所有回答都要落到 RootData 类 Web3 主项目、Agent Bot、Text2SQL、RAG、runId/evidence/artifact/data pack 和下游报告 Agent 复用。
Q&A20 组高强度追问
面试官:融资公告、新闻、项目方提交、第三方 API 冲突时听谁的?
我:我会按 source priority 和字段类型判断。融资金额优先官方公告或投资机构公告,行情优先可信市场 API,社区提交只能做候选。答案里展示主值和冲突来源,触发数据修复。
数据冲突、来源优先级与时效性:时效一致章主讲多源冲突和 source priority,RAG 与可信结果章只补充证据侧处理。
- 03-rag-optimization · q06
- 03-rag-optimization · q17
- 07-trustworthy-results-evidence-chain · q08
- 07-trustworthy-results-evidence-chain · q18
- 12-freshness-source-consistency · q05
- 12-freshness-source-consistency · q11
- 12-freshness-source-consistency · q13
- 12-freshness-source-consistency · q14
- 12-freshness-source-consistency · q18
理解与记忆 · 背后工程点
背后工程点:多源冲突不能交给模型拍脑袋。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:Token 解锁数据更新后,缓存和索引怎么失效?
我:unlock_events 更新会影响项目详情、解锁榜、风险评分、RAG chunks 和相关 report data pack cache。缓存 key 带数据版本和更新时间,变更后按实体和指标依赖失效。
缓存、物化视图与批量性能:性能章主讲缓存/物化/批量保护,优化章和复杂分析章只补充业务场景。
- 14-performance-cost-concurrency · q02
- 06-optimizations · q04
- 06-optimizations · q08
- 06-optimizations · q14
- 10-complex-analysis-planning · q09
- 10-complex-analysis-planning · q18
- 14-performance-cost-concurrency · q03
- 14-performance-cost-concurrency · q04
- 14-performance-cost-concurrency · q07
- 14-performance-cost-concurrency · q13
理解与记忆 · 背后工程点
背后工程点:缓存失效要按数据依赖传播。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:答案里是否展示数据更新时间?
我:高风险和时效性问题必须展示。比如“未来 30 天解锁压力”要给 token_unlock_events 的更新时间和来源;融资周报要给统计截止时间。
理解与记忆 · 背后工程点
背后工程点:新鲜度要进入用户可见交付。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:score_snapshots 如何回答“最近上涨”?
我:先锁定时间窗口,比如 7d 或 30d,再取窗口起点和终点的分数变化,必要时使用日均或移动平均,避免单点波动误导。
理解与记忆 · 背后工程点
背后工程点:时序指标要定义窗口和比较方法。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:多源合并时为什么保留 source_documents?
我:因为最终字段只是当前主值,source_documents 才能解释它来自哪里、是否冲突、何时采集。没有原始来源,报告 Agent 不能可信引用。
数据冲突、来源优先级与时效性:时效一致章主讲多源冲突和 source priority,RAG 与可信结果章只补充证据侧处理。
- 12-freshness-source-consistency · q01
- 03-rag-optimization · q06
- 03-rag-optimization · q17
- 07-trustworthy-results-evidence-chain · q08
- 07-trustworthy-results-evidence-chain · q18
- 12-freshness-source-consistency · q11
- 12-freshness-source-consistency · q13
- 12-freshness-source-consistency · q14
- 12-freshness-source-consistency · q18
理解与记忆 · 背后工程点
背后工程点:结构化字段和来源证据都要保留。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:行情 API 最新但项目详情表滞后怎么办?
我:answer 标记数据源更新时间差异。市场字段用最新 API,项目基本信息提示可能滞后,并把 data freshness 写进 evidence。
理解与记忆 · 背后工程点
背后工程点:不同数据域的新鲜度可能不同。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:报告 Agent 生成周报时如何冻结快照?
我:创建报告 run 时锁定 timeRange、snapshotTime、semanticVersion、indexVersion 和 source cutoff。之后报告段落都引用这个 data pack,不随后台更新自动变化。
理解与记忆 · 背后工程点
背后工程点:报告需要可复现快照。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:老板隔天打开同一个 runId,看到当时结果还是最新结果?
我:runId 回放应该看到当时结果和证据。可以提供“用最新数据重新运行”按钮生成新 runId,但不能直接改写历史 run。
Semantic version 与指标口径回放:语义层主讲口径版本锁,架构和时效章补充 runId 回放与历史报告。
理解与记忆 · 背后工程点
背后工程点:回放和重跑要分开。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:数据新鲜度是否参与置信度?
我:应该参与。证据越旧、来源级别越低、结构化更新时间越落后,置信度越低,riskTags 里标 stale evidence 或 source lag。
理解与记忆 · 背后工程点
背后工程点:置信度要考虑时效性。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:增量采集失败时如何避免返回过期确定结论?
我:健康检查和 ingestion metrics 会标记采集滞后。查询命中受影响数据域时,delivery 降级提示数据可能过期,严重时拒绝高风险结论。
理解与记忆 · 背后工程点
背后工程点:采集失败要反映到查询交付。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:如何设计 source priority?
我:按数据类型分层配置,比如官方公告、链上/交易所、权威媒体、数据供应商、项目方提交、社区提交。每类字段可有不同优先级和冲突策略。
数据冲突、来源优先级与时效性:时效一致章主讲多源冲突和 source priority,RAG 与可信结果章只补充证据侧处理。
- 12-freshness-source-consistency · q01
- 03-rag-optimization · q06
- 03-rag-optimization · q17
- 07-trustworthy-results-evidence-chain · q08
- 07-trustworthy-results-evidence-chain · q18
- 12-freshness-source-consistency · q05
- 12-freshness-source-consistency · q13
- 12-freshness-source-consistency · q14
- 12-freshness-source-consistency · q18
理解与记忆 · 背后工程点
背后工程点:来源优先级不是全局一刀切。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:索引更新后答案变了,怎么判断原因?
我:比较两个 runId 的 snapshot、semanticVersion、indexVersion、selected evidence 和 SQL artifact。若数据版本变了是事实更新,若证据召回变了是索引或检索策略变化。
理解与记忆 · 背后工程点
背后工程点:版本对比能区分数据更新和系统漂移。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:source_documents 中旧新闻还会被召回怎么办?
我:检索和 rerank 要加入时效权重、版本过滤和 source validity。旧新闻可以作为历史背景,但不能覆盖当前有效公告。
数据冲突、来源优先级与时效性:时效一致章主讲多源冲突和 source priority,RAG 与可信结果章只补充证据侧处理。
- 12-freshness-source-consistency · q01
- 03-rag-optimization · q06
- 03-rag-optimization · q17
- 07-trustworthy-results-evidence-chain · q08
- 07-trustworthy-results-evidence-chain · q18
- 12-freshness-source-consistency · q05
- 12-freshness-source-consistency · q11
- 12-freshness-source-consistency · q14
- 12-freshness-source-consistency · q18
理解与记忆 · 背后工程点
背后工程点:旧证据要降权或标历史。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:项目方提交信息和公开来源冲突怎么办?
我:项目方提交可以提高处理优先级,但仍需要验证。未验证前作为 pending source,不进入 production 主值或只带低置信标签。
数据冲突、来源优先级与时效性:时效一致章主讲多源冲突和 source priority,RAG 与可信结果章只补充证据侧处理。
- 12-freshness-source-consistency · q01
- 03-rag-optimization · q06
- 03-rag-optimization · q17
- 07-trustworthy-results-evidence-chain · q08
- 07-trustworthy-results-evidence-chain · q18
- 12-freshness-source-consistency · q05
- 12-freshness-source-consistency · q11
- 12-freshness-source-consistency · q13
- 12-freshness-source-consistency · q18
理解与记忆 · 背后工程点
背后工程点:项目方输入也需要审核。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:多语言来源会影响一致性吗?
我:会。需要实体统一、时间统一和 source normalization。不同语言报道同一融资事件要合并到同一 event,避免重复计数。
理解与记忆 · 背后工程点
背后工程点:多源一致性也包括跨语言去重。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:如何避免周报重复统计同一融资事件?
我:以 funding event 的 canonical id、项目、日期、金额、lead investor 和 source checksum 去重。RAG 证据可以多条,但结构化事件只算一次。
理解与记忆 · 背后工程点
背后工程点:事件主数据要防重复。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:Calendar 未来事件取消了,历史报告怎么办?
我:历史报告保留当时快照,同时在最新视图里显示事件状态已变更。如果用户重跑报告,会使用新状态。
理解与记忆 · 背后工程点
背后工程点:历史事实和当前事实要分层。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:如何处理低质量来源覆盖官方公告?
我:merge 规则禁止低优先级来源覆盖高优先级主值,只能添加补充证据或待审核冲突。覆盖需要审核或更高可信来源。
数据冲突、来源优先级与时效性:时效一致章主讲多源冲突和 source priority,RAG 与可信结果章只补充证据侧处理。
- 12-freshness-source-consistency · q01
- 03-rag-optimization · q06
- 03-rag-optimization · q17
- 07-trustworthy-results-evidence-chain · q08
- 07-trustworthy-results-evidence-chain · q18
- 12-freshness-source-consistency · q05
- 12-freshness-source-consistency · q11
- 12-freshness-source-consistency · q13
- 12-freshness-source-consistency · q14
理解与记忆 · 背后工程点
背后工程点:source priority 要在写入和查询都生效。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:数据时效性的评测怎么做?
我:构造数据变更样本,验证缓存失效、索引版本、快照回放、冲突展示和 stale 标签。指标看 stale read rate、冲突识别率、快照复现率。
评测、badcase 与回归门禁:评测章主讲体系,优化、安全、观测和性能章只补各自维度的验收。
- 09-evaluation-badcase-loop · q01
- 06-optimizations · q17
- 08-permission-security-governance · q19
- 09-evaluation-badcase-loop · q06
- 09-evaluation-badcase-loop · q09
- 09-evaluation-badcase-loop · q13
- 09-evaluation-badcase-loop · q14
- 09-evaluation-badcase-loop · q18
- 09-evaluation-badcase-loop · q19
- 13-observability-troubleshooting · q15
- 13-observability-troubleshooting · q19
- 14-performance-cost-concurrency · q17
理解与记忆 · 背后工程点
背后工程点:新鲜度也需要回归测试。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
面试官:一句话总结时效性设计。
我:我的设计是让每个答案都带着来源、时间、版本和冲突信息出现,确保它是某个数据快照下可证明的结论。
理解与记忆 · 背后工程点
背后工程点:总结要强调版本化和可证明。
专业术语:Freshness:数据或证据相对当前问题是否足够新。
Source Priority:多来源冲突时判断可信来源的优先级规则。
Snapshot:某个时间点冻结的数据视图,用于报告复现。
为什么这样回答:时效性题不能只说定时同步。面试官要听到来源、版本、缓存、索引、快照和冲突如何进入回答。
小白解析:同一个项目今天刚融资,明天 Token 解锁计划又变了。系统要告诉你它查的是哪个时间点的数据,来源是谁,有没有旧数据混进来。
关联知识点:RootData 类主项目的数据包含融资、Token Unlock、Calendar、评分、新闻和行情。text2sql 的 runId replay、delivery.evidence、semanticVersion 和 indexVersion 可以支撑时效性回放。
PRINCIPLE本章背诵原则
- Web3 数据答案必须带来源和时间。
- 多源冲突要显式展示和治理。
- 报告使用快照,历史 runId 不自动漂移。
- 缓存和索引必须感知数据版本。
- 过期证据要降级,不要伪装成确定事实。