OPENING30 秒开口版
Text2SQL 不是 prompt 写 SQL,而是一套可验证问数操作系统。完整运行先确认 active schema catalog 和 actor/workspace 权限,再把用户问题抽成 QuerySlots;retrieve 召回 schema、glossary、metric definition、relationship、source evidence 和历史 SQL 样例;assemble-context 只保留授权后的 selected context;planner 生成 IntentPlan、SemanticPlan 和 PhysicalSqlPlan;generate-sql 只是把 plan 编译成结构化 SQL 草案;validate 做 plan check、AST、readonly、single statement、schema/ACL、limit、dry-run 和 semanticPlanMatched;correct 只修 correctable error;execute 后 answer 只能基于 SQL、columns、rows、assumptions 和 evidence 形成 grounded answer,并用 runId 持久化 replay 和 eval case。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | QuerySlots:问题类型、指标、维度、过滤、时间范围、实体和歧义的结构化投影。 Selected Context:经过检索、权限过滤、重排和 token budget 控制后给生成阶段使用的上下文。 PhysicalSqlPlan:SQL 生成前的表、列、join、聚合、过滤、排序和 limit 合同。 Grounded Answer:只基于执行结果和记录假设生成的回答。 Replay:按 runId 回放 selected context、plans、SQL、validation、correction、execution 和 answer。 |
| 为什么这样回答 | 开口先讲“查询编译过程”,能避免被面试官误解成调 prompt。重点是 SQL 前有事实和计划,SQL 后有验证、执行证据和回放。 |
| 小白解析 | 用户问一句话,系统不是马上写 SQL,而是先确认数据目录和权限,再找相关表、字段、指标和关系,制定查询计划,写 SQL,质检,执行,最后只按查询结果回答。 |
| 关联知识点 | text2sql README 和架构文档把 v2 主链固定为 Text2SQLWorkflowRunner -> RunV2LangGraphStage -> Text2SqlV2LangGraphRunnerService。新范式把这条主链解释为 Source of Truth -> State Projection -> Query Compiler -> SQL Draft -> Validator/Executor -> Grounded Answer -> Replay/Eval。 |
1 MIN一分钟口语版
如果展开讲,我会把每一步都讲成对象传递。Datasource Ready 后先做 schema ingestion,生成 active SchemaCatalogVersion;用户提问时 intake 生成 run envelope,绑定 actor、workspaceId、datasourceId、policyVersion、agent scope、riskLevel、dialect 和 runId。Intent Service 抽 QuerySlots,判断是 lookup、detail、aggregate、trend、compare 还是 ranking,并记录缺失槽位和假设。Knowledge Service 不全量拿 schema,而是按权限召回 table/column、relationship、metric definition、glossary、source evidence、historical SQL example,再过滤成 SelectedContextPack。Planner 生成 IntentPlan、SemanticPlan、PhysicalSqlPlan,并先做 plan validation。LLM 只在这个上下文里输出 SqlGenerationOutput,包括 sql、referencedTables、referencedColumns、assumptions、confidence 或 cannotAnswerReason。Validator 再做 AST、single statement、readonly、schema existence、ACL、limit、dry-run 和 semanticPlanMatched;UNKNOWN_COLUMN、GROUP_BY、DIALECT 这类可纠错,READONLY、ACL、未解析引用、危险函数必须 terminal。最后 executor 返回 columns、rows 和 summary,Answer Formatter 只能基于结果集和记录假设回答,并把 replay 完整保存成后续评测资产。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | SchemaCatalogVersion:某个数据源的 active schema 快照版本。 Route:把请求分流到 SQL、metadata、澄清、安全拒绝等路径。 SqlGenerationOutput:模型生成的结构化 SQL 草案,不是最终事实。 Dry-run:执行前检查 SQL 可行性、成本和字段权限。 Fail-closed:不确定或越权时默认不执行。 |
| 为什么这样回答 | 一分钟版要把主路径、对象合同和分支都讲到,面试官会听出你知道 SQL 失败、权限不明、metadata answer、空结果和可回放怎么处理。 |
| 小白解析 | 像一个有质检的流水线:先确认仓库目录和谁有权限,再理解订单、准备材料、制定生产计划、生产 SQL、质检、出货和留档。 |
| 关联知识点 | 架构文档说明 metadata 问题不一定走 SQL,semantic-plan 可以决定继续 SQL、直接回答、澄清或 fail-closed。新范式进一步要求计划、SQL 和回答都可验证。 |
FLOW GOALS流程设计目标
不是裸 SQL 生成
Text2SQL 是一次查询编译运行,前面要有事实源、QuerySlots、selected context、语义计划和权限边界。
支持多入口
老板问数、投研查询、下游报告 Agent 调用都走同一条 runId 链路,但输出形态不同。
支持多执行计划
简单统计走 SQL,项目新闻走搜索,机构共投走图查询,趋势问题可能要拆成多个 PhysicalSqlPlan 后合并。
权限先于 prompt
未授权 datasource、table、column 不允许进入 selected context,执行前再做 AST 和 ACL 二次校验。
失败可分类
空结果、SQL 错误、低置信召回、权限不足要区分 terminal、correctable、clarification 和 metadata answer。
回答可验证
Answer Formatter 只能使用 question、final SQL、columns、rows、assumptions、metric definitions 和 evidence。
DIAGRAMText2SQL 运行时主链路
从问题到可回放交付
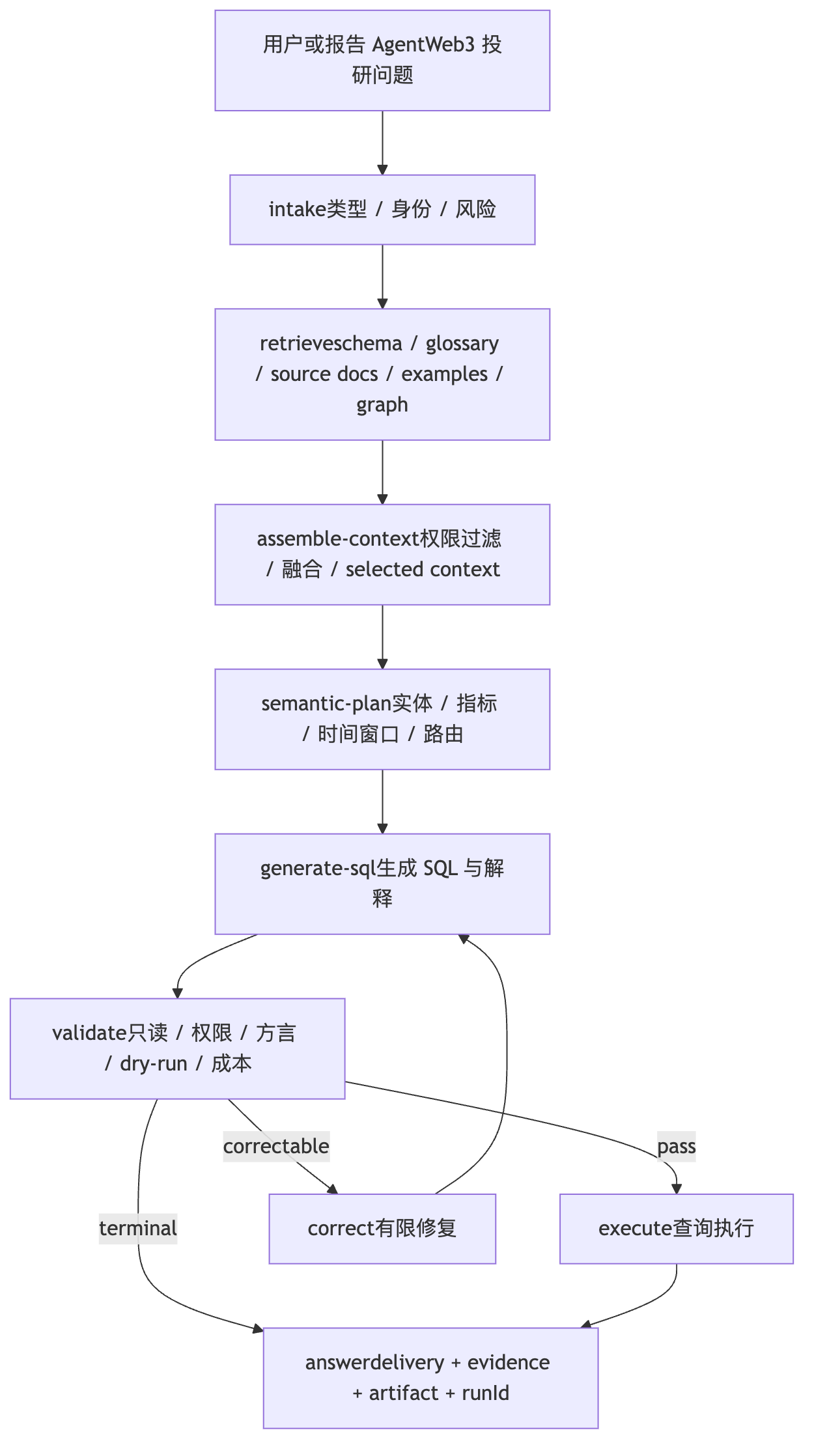
Query Planner 如何选择执行引擎
TABLE关键节点和面试讲法
| 节点 | 职责 | 面试时要强调 |
|---|---|---|
| schema-ready | 确认 datasource 可用、active schema catalog 存在、dialect 明确。 | 没有可信 schema,就不要假装系统知道数据库结构。 |
| intake / slots | 分类问题、识别风险、绑定身份和 workspace,抽取 QuerySlots。 | 它决定后续是否进入 SQL、澄清、metadata answer 或 fail-closed。 |
| retrieve | 召回 schema、术语、指标、关系、来源文档、样例和图谱。 | SQL 生成前要先有证据,不是让模型凭表名猜。 |
| assemble-context | 过滤权限、融合多路证据、控制预算、形成 SelectedContextPack。 | 模型看到的上下文应该已经是授权后的世界。 |
| plan | 生成 IntentPlan、SemanticPlan、PhysicalSqlPlan 并校验。 | 计划不是 trace 装饰,而是 SQL 生成前的结构化合同。 |
| generate-sql | 基于 selected context 和 plans 输出 SqlGenerationOutput。 | SQL 是草案;referencedTables 和 referencedColumns 要供 validator 交叉检查。 |
| validate/correct | 做 AST、只读、单语句、schema、ACL、limit、dry-run、语义对齐和有限修复。 | 可修复错误有限重试,越权、危险 SQL 和未解析引用直接终止。 |
| execute/answer/replay | 执行查询,格式化 grounded answer,持久化 replay 和 eval case。 | 交付同时服务人类界面、下游报告 Agent 和后续评测。 |
面试里要反复强调:Text2SQL 的难点不是“写出能跑的 SQL”,而是让 SQL 来自正确事实源、使用正确口径、在正确权限内执行,并且回答忠于结果、运行可回放。
CONTRACT核心对象字段
| 对象 | 关键字段 | 高强度追问时的回答重点 |
|---|---|---|
| querySlots | queryType、metrics、dimensions、filters、timeRange、entities、sort、limit、ambiguities、confidence | 先理解问题,再决定继续、澄清、默认假设或拒绝。 |
| selectedContextPack | datasourceId、catalogVersionId、dialect、acl、selectedTables、relationships、metrics、examples、evidence | 模型只能看到授权后的上下文;无权、过期、低置信、冲突未说明的材料不能进入这里。 |
| semanticPlan / physicalSqlPlan | resolvedMetrics、resolvedDimensions、resolvedFilters、requiredRelationships、assumptions、tables、columns、joins、aggregations、filters、groupBy、orderBy、limit | 它不是 prompt 里的自由文本,而是 generate-sql 和 validate 都要遵守的结构化计划。 |
| sqlGenerationOutput | sql、explanation、referencedTables、referencedColumns、assumptions、confidence、cannotAnswerReason | 模型输出的是 SQL 草案和自证引用,validator 要交叉检查,不能从 markdown code block 里随便抽 SQL。 |
| sqlValidationReport | astParsed、statementType、readonly、tables、columns、deniedRefs、costEstimate、dryRunStatus、semanticPlanMatched、reasonCode、correctable | 把 pass、correctable、terminal 分清楚;权限、危险 SQL、AST 不完整不能让模型继续修。 |
| groundedAnswer / replay | question、finalSql、columns、rows、assumptions、metricDefinitionsUsed、runId、selectedContext、plans、validation、executionSummary、finalStatus | 可信不是模型语气,而是每个结论都能回到表、字段、来源、语义版本、权限版本和运行轨迹。 |
如果面试官追问“给我讲对象 schema”,不要只报字段名,要顺带解释字段如何约束下一步:querySlots 决定澄清,selectedContext 约束模型可见世界,plans 约束 SQL,sqlGenerationOutput 暴露模型引用,validationReport 决定能否修复,groundedAnswer/replay 决定能否给报告 Agent 引用和事后评测。
INTERVIEW MAP面试表达地图
- 先定定位Text2SQL 是 Query OS 的结构化查询编译器,不等于 LLM 写 SQL。
- 再讲主链schema-ready、intake/slots、retrieve、assemble-context、plan、generate-sql、validate/correct、execute、grounded answer、replay。
- 强调对象QuerySlots、SelectedContextPack、IntentPlan、SemanticPlan、PhysicalSqlPlan、SqlGenerationOutput、ValidationReport、Text2SqlReplay。
- 落到 RootData项目、机构、融资、Token、解锁、评分、关系图谱这些 Web3 资产是事实源和执行对象。
- 收束价值结果以 grounded answer、artifact、data pack、runId 和 eval case 给人、报告 Agent 和系统迭代复用。
SUBAGENTS面试官和候选人模拟
本章继续沿用第一章的两个 subagent 视角:面试官 subagent 负责追问架构边界、失败模式、评测、治理和下游报告 Agent;候选人 subagent 负责把回答压成现场能讲出来的中文,并且把每个观点落到流程节点、数据对象、合同或工程权衡。
本章追问重点:Text2SQL 是不是只有 SQL?SQL 前的证据和语义从哪里来?SQL 后的治理和交付怎么保证可信?
Q&A20 组高强度追问
面试官:你说 Text2SQL 是流程,不是一个 prompt。那完整主链路到底怎么走?第二层追问:哪一步最容易出错?
我会按对象流讲,而不是只背节点名。先确认 datasource 有 active schema catalog,然后 intake 生成带 actor、workspaceId、datasourceId、policyVersion、agent scope、riskLevel、dialect、runId 的 run envelope;Intent Service 把问题抽成 QuerySlots;retrieve 召回授权后的 schema、glossary、metric definition、relationships、source evidence 和 historical SQL;assemble-context 形成 SelectedContextPack;planner 输出 IntentPlan、SemanticPlan、PhysicalSqlPlan 并先校验计划;generate-sql 只是把 plan 落成 SqlGenerationOutput;validate 再看 AST、single statement、readonly、schema/ACL、limit、dry-run、成本和 semanticPlanMatched;execute 后 answer 只基于 rows、columns、SQL 和已记录假设回答,并保存 replay。最容易出错的不是 SQL 语法,而是 schema linking、join path、时间窗口和业务口径,SQL 能跑但业务错比执行失败更危险。
运行时主链路与节点命名:流程章主讲当前 runtime 链路,架构和踩坑章只解释历史命名差异。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:用户问“最近哪些 AI x Crypto 项目融资热度最高”,你怎么拆成实体、指标、时间窗口和排序逻辑?
先在 intake 抽 QuerySlots:这是 ranking/analysis,实体域是 project,业务标签是 AI x Crypto,指标可能是融资热度,时间范围是“最近”,排序是热度最高。retrieve 要找 AI x Crypto 标签定义、项目实体、funding_rounds、score_snapshots、metric definition 和可用 join path。semantic-plan 再把“融资热度”解析成金额、轮次、投资人质量和时间窗口,PhysicalSqlPlan 决定表、列、过滤、聚合、排序和 limit;如果“融资热度”有多个口径,就先澄清或使用默认并在 answer 里说明假设。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:Text2SQL 在 Agent Bot 里是主链路还是工具链路?什么时候不用 SQL?
它是结构化数据查询的主工具,但不是所有问题都走 SQL。查项目来源、新闻公告、白皮书引用时更适合 RAG/搜索;查共同投资网络或生态路径时更适合图查询;问“这个指标是什么意思”时可以走 metadata answer。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:SQL 生成前,如何限制模型只能使用被授权、被建模过的表和字段?
限制不靠 prompt 口头提醒,而是在 prompt 前做权限裁剪:resolve actor/workspace 后先过滤 visible datasources、tables、columns 和 row policy metadata,再由 retrieve/assemble-context 只构造授权后的 SelectedContextPack。模型看不到未授权 schema,自然不能基于它生成 SQL。validate 阶段还会抽取 referencedTables 和 referencedColumns,和 policyVersion、selected context、plan 逐项对齐;解析不完整、引用未授权对象、只读违规、多语句或危险函数都 fail-closed。
权限校验位置与 fail-closed:权限章主讲治理边界,流程、安全和踩坑章复用同一原则。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
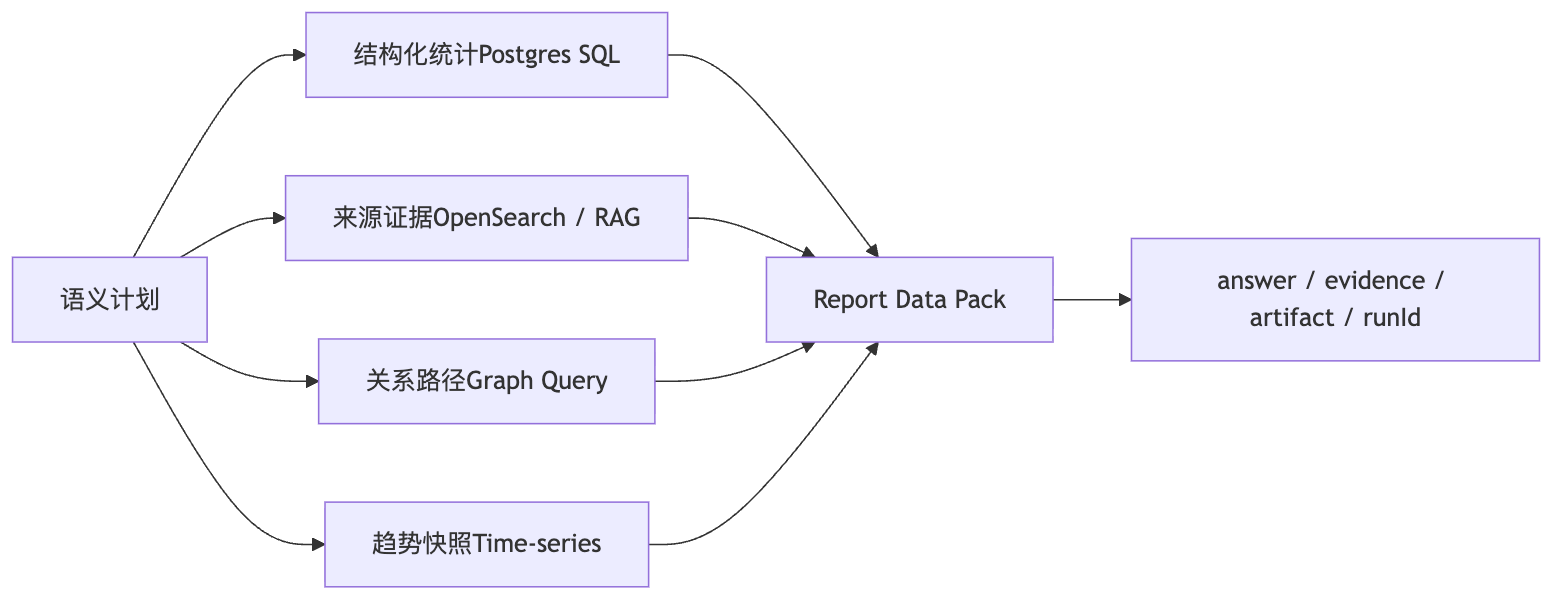
面试官:Query Planner 怎么判断单 SQL、多 SQL、SQL + RAG,还是 SQL + Graph?
semantic-plan 会看问题是否只需要聚合统计,还是需要来源证据、关系路径或时间趋势。比如融资榜单可以单 SQL,项目尽调需要 SQL + RAG,机构共投需要 SQL + Graph,趋势报告可能多 SQL 加时序指标。
Query Planner 路由与避免全工具执行:流程章主讲路由判断,优化章主讲降本,复杂分析章主讲计划拆分。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:生成 SQL 后有哪些校验层?语法、权限、成本、语义分别放哪里?
validate 分两层。第一层是 plan validation:PhysicalSqlPlan 里的 table、column、join、metric formula、limit、dialect 必须存在、授权且有 evidence。第二层才是 SQL validation:解析 AST,确认单语句 readonly,拒绝 DDL/DML、多语句、危险函数、系统 schema 和注释绕过;再抽取 tables、columns、joins、filters,和 policyVersion、selected context 对齐;然后 dry-run 看方言、limit、扫描范围和 costEstimate;最后做 semantic alignment,比如 plan 要未 TGE,SQL 里必须有 token_status 或 tge_date 约束。validation report 要带 reasonCode 和 correctable,决定是 pass、bounded correction,还是 terminal fail-closed。
SQL 校验、执行安全与 correct loop:架构章主讲 validate/correct/execute 是主链路,安全章主讲攻击面和终止条件。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:如果用户问题里有“头部机构”“优质项目”“近期热度”这种模糊词,流程里谁来解释?
不应该由 generate-sql 临场猜。glossary 和 semantic registry 定义这些词的口径,retrieve 找到相关定义,semantic-plan 把它们变成可执行条件,比如机构等级、lead 次数、投资组合质量、近 30 天热度变化。
业务语义、模糊词与默认口径:语义映射章主讲业务词如何落表,语义层和澄清章主讲默认与追问边界。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:下游报告 Agent 调用 Text2SQL 时,输出为什么不能只是 SQL 结果表?
报告 Agent 需要写可引用内容,所以它要的不只是 rows,还需要 evidence、artifact、chart spec、字段口径、来源和 runId。否则报告文字出了问题,无法判断是 SQL 错、证据错还是报告 Agent 叙事夸大。
证据链、data pack 与报告可追溯:可信结果章主讲 evidence/data pack 合同,其他章只补充报告 Agent 消费与复用场景。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:SQL 执行失败、空结果、结果异常偏大时,系统怎么降级?
可修复错误进入 bounded correction;权限、危险 SQL、解析不完整直接 fail-closed;空结果要区分真实无数据、时间窗口过窄、实体没解析对;结果过大则触发 limit、聚合建议或澄清。
空结果解释、评测与排查:可信结果章主讲空结果怎么可信解释,评测和可观测章分别处理验证与排查。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:怎么保证一次 Text2SQL 调用可以被 replay?
runId 贯穿 intake、retrieval bundle、selected context、semantic-plan、SQL、validation、execution summary 和 delivery。复盘时不重新猜当时发生了什么,而是按 runId 回看每一步的输入输出和降级原因。
runId、trace、replay 与回放:可信结果章主讲 runId 可回放,架构、流程、时效和可观测章只从各自链路补充。
- 07-trustworthy-results-evidence-chain · q01
- 01-business-architecture · q13
- 05-pitfalls-architecture-evolution · q08
- 07-trustworthy-results-evidence-chain · q12
- 10-complex-analysis-planning · q11
- 12-freshness-source-consistency · q08
- 13-observability-troubleshooting · q01
- 13-observability-troubleshooting · q02
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:如果 RAG 检索没找到正确 schema,但 LLM 依然生成了一条能跑的 SQL,你怎么处理?
能跑不代表正确。selected context 如果缺少 must-have schema、metric definition 或 join path,semantic-plan 应该标记低置信、返回 cannotAnswerReason 或要求澄清;plan validation 也应该先失败。即使数据库执行成功,validator 仍要检查 SQL 是否引用计划外表字段、是否满足 semanticPlanMatched、是否用了正确时间字段和指标公式。业务错 SQL 比语法错更危险,因为它会给用户一个看似可信的错误答案。
RAG 召回为空、低置信与降级:RAG 章主讲搜不到时如何表现,架构和澄清章补充继续、澄清、fail-closed 的边界。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:metadata 问题为什么不一定进入 SQL?比如“融资强是怎么定义的?”
这是口径解释,不是数据查询。它可以走 retrieve -> assemble-context -> semantic-plan -> answer,直接基于 glossary 或 semantic registry 回答,并附上版本和来源,不需要生成 SQL。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:correct loop 为什么要有预算?为什么不能一直让模型修到成功?
correct loop 是为了修可执行性,不是给模型绕过治理。列名轻微错误、方言差异、limit 缺失、聚合写法问题可以带 validation reason 回到 generate-sql,但有 retry budget。越权字段、多语句、DDL/DML、危险函数、AST 无法确认表字段、must-have evidence 缺失、semantic-plan 不满足都属于 terminal,直接 fail-closed 或澄清。否则模型可能把“不能查”修成“换个字段偷偷查”。
SQL 校验、执行安全与 correct loop:架构章主讲 validate/correct/execute 是主链路,安全章主讲攻击面和终止条件。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:Text2SQL 如何处理时间窗口?Web3 里“最近”“本周”“下个月解锁”都很常见。
intake 会记录当前时间和用户时区,semantic-plan 把相对时间变成绝对窗口,并绑定到正确字段,比如 funding_rounds.announced_date、token_unlock_events.unlock_date、score_snapshots.date。delivery 里也要显示口径,避免报告引用时混淆。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:多租户或套餐权限对 Text2SQL 流程有什么影响?
权限不只影响 execute,还影响检索和上下文。不同 workspace、API key、套餐、agent scope 看到的 schema、字段、来源和数据包不同,模型只能基于授权后的 selected context 生成 SQL。
权限校验位置与 fail-closed:权限章主讲治理边界,流程、安全和踩坑章复用同一原则。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:如果老板问的是咨询问题,比如“这个项目基本面怎么样”,Text2SQL 在里面怎么发挥作用?
它会成为组合分析的一部分。项目基本面需要 SQL 查融资、团队、Token、评分和事件,也需要 RAG 查来源和新闻,还可能用图查询看投资人关系,最后由 delivery 合成有证据的投研解释。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:SQL 执行结果如何变成自然语言答案?
answer 阶段不是简单把 rows 贴给模型,而是 Grounded Answer。输入只能是 question、finalSql、columns、rows、assumptions、metric definitions used 和 evidence,不能补充结果集之外的数据,也不能把假设说成事实。明细题展示行数和字段,聚合题突出指标值和口径,排名题说明 topN 和排序依据,趋势题说明周期和变化,空结果说明过滤条件下没有匹配。人看结论,分析师看 SQL artifact,报告 Agent 拿 data pack,runId 支撑回放。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:怎样避免 Text2SQL 生成错误 join?
join path 不应该靠 LLM 猜。Modeling Layer 维护 relationships,RAG 召回相关关系,semantic-plan 锁定路径,SQL 生成只能在这些路径内组合,validate 阶段再检查引用是否符合授权关系。
Schema linking、schema 变更与 join path:语义映射章主讲 join path,流程和优化章只从生成稳定性角度补充。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:如果一个问题需要跨数据源,比如项目库加链上指标,Text2SQL 怎么办?
不能硬写一条 SQL。planner 要拆成多个 physical plan,分别走主库、时序或外部指标适配器,再在 delivery 阶段合并成 data pack,并标明来源、时间戳和置信度。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:面试官问“你这个流程和普通 ChatBI 有什么差别”,你怎么回答?
普通 ChatBI 往往关注自然语言到 SQL,这里更像 Query OS。差别在于:第一,事实源和 prompt 分离,schema catalog、metric definition、policy、source documents 是可审计资产;第二,权限在 prompt 前裁剪,未授权 schema 不进 selected context;第三,先有 QuerySlots、SemanticPlan、PhysicalSqlPlan,再生成结构化 SQL 草案;第四,plan 和 SQL 都要验证,安全拒绝和可修复错误分开;第五,最终 answer 必须忠于 rows/columns/evidence,并用 runId 保存 replay,持续转成 eval case。
理解与记忆 · 背后工程点
背后工程点:回答 Text2SQL 流程时,要把自然语言问题拆到运行时节点,而不是只说“LLM 生成 SQL”。
专业术语:Intake 是识别问题类型、风险和调用方身份的入口阶段;Semantic Plan 是把检索到的证据转成可执行语义计划的阶段;Delivery Contract 是把答案、证据、SQL 工件和 runId 统一交付的结构。
为什么这样回答:这样回答能体现你理解了主链路、失败分支和交付边界。
小白解析:不是用户问一句就让模型写 SQL,而是先理解问题、找资料、定计划、校验 SQL,再执行和交付。
关联知识点:text2sql README 明确主链路为 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。
面试官:Text2SQL Prompt 应该放哪些内容?DDL、字段注释、样例值、历史 SQL、业务规则都要塞进去吗?
我不会把所有材料都塞进 prompt,而是由 selected context 和 semantic-plan 决定最小必要输入。通常会放:目标问题、数据库方言、允许使用的表列、字段业务含义、指标口径、join path、时间窗口、权限约束、少量样例值、输出 SQL schema 和禁止事项。历史 SQL 和 few-shot 只有在和当前问题结构高度相似且已授权时才放;业务规则优先来自 semantic registry,而不是散落在 prompt 里。最后要求模型输出结构化 SQL 草案和字段引用理由,再由 validate/correct/execute 接管,不让 prompt 成为唯一安全边界。
理解与记忆 · 背后工程点
背后工程点:Prompt 是编译输入视图,不是所有知识的仓库。
专业术语:Few-shot 是少量示例提示;SQL Dialect 是 MySQL、PostgreSQL、Hive、SparkSQL 等方言;Schema Context 是授权后的表列和关系输入;Semantic Registry 是指标和业务规则事实源。
为什么这样回答:Prompt 设计题要体现上下文预算、权限、安全和校验链路,而不是只列“DDL + 示例”。
小白解析:给模型写 SQL 像给工程师一张任务单:只给这次需要的表、字段、规则和例子,不把整个公司数据库手册都摊开。
关联知识点:本章主链路强调 retrieve、assemble-context、semantic-plan、generate-sql、validate/correct/execute 的分层。
PRINCIPLE本章背诵原则
- 主链要完整:一定说出 schema-ready、intake/slots、retrieve、assemble-context、plan、generate-sql、validate/correct、execute、grounded answer、replay。
- SQL 不是起点:SQL 来自 selected context、semantic plan 和 physical plan,不是模型凭空生成。
- 权限要前置:未授权表列不能进入 prompt,execute 前还要做 ACL 二次校验。
- 校验要分层:先校验 plan,再校验 SQL;correctable 和 terminal 必须分清楚。
- 回答要忠实:answer 只能基于 SQL、columns、rows、assumptions 和 evidence,不允许编故事。
- 交付要复用:answer 给人看,artifact 给分析师查,data pack 给报告 Agent 用,runId/replay 用于回放和评测。