OPENING30 秒开口版
我会把优化分成准确率、可信度、性能和可运维性四条线。准确率上,补 semantic registry、join path、SQL validate/correct 和 RAG evidence;可信度上,做权限前置、source confidence、delivery contract、runId 和 replay;性能上,给高频报告任务做缓存、物化视图、数据包复用和 planner 路由,避免每次 SQL + RAG + Graph 全跑;可运维性上,建立 RAG gold evidence 评测、SQL 错误分类、慢查询、低置信召回、报告引用失败监控。我的优化不是只改 prompt,而是把系统从“能答”优化到“答得准、能证明、跑得稳、可复盘”。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | 系统级优化:同时优化准确率、治理、性能、成本和可观测性 Planner Routing:根据问题选择必要执行引擎,避免全量工具调用 Data Pack Cache:复用报告 Agent 常用数据包 Ablation:逐项开关优化手段验证真实收益 |
| 为什么这样回答 | 开口要先分层,避免被面试官听成“我调了 prompt”。 |
| 小白解析 | 优化不是只让模型更会说,而是让整个系统更准、更快、更省、更容易查错。 |
| 关联知识点 | text2sql 强调 governed、executable、replayable;learn-RAG 强调用评估闭环驱动索引和检索优化。 |
1 MIN一分钟口语版
如果展开讲,我会按八类优化讲。第一是语义层优化,把未 TGE、融资强、热度上涨、顶级投资人这些口径沉到 semantic registry。第二是 RAG 优化,做 metadata、alias、hybrid search、graph retrieval、RRF/rerank 和 gold evidence 评测。第三是 SQL 准确率优化,用 selected context、join path、smart defaults、validate、dry-run 和 bounded correction。第四是实体解析优化,减少项目重名、Token symbol 重复、机构别名。第五是 planner 优化,根据任务决定走 SQL、搜索、图谱、时序或组合计划。第六是性能优化,高频榜单、融资周报、Token 解锁风险用缓存、物化视图和 data pack 复用。第七是成本优化,减少不必要 LLM 轮次、分层模型、限制上下文和异步长任务。第八是观测优化,用 runId 打通 trace、RAG replay、SQL artifact、错误分类和报告引用链路。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Smart Defaults:在时间窗口、排序、limit 等不明确时使用受控默认值 Materialized View:预计算常用统计或榜单以降低实时查询成本 Error Taxonomy:错误分类体系,用于定位召回、语义、SQL、权限或生成问题 Async Report Job:长报告任务的异步执行模式 |
| 为什么这样回答 | 一分钟版覆盖八类优化,能体现你考虑的是生产系统,而不是单点效果。 |
| 小白解析 | 把常问的提前算好,把容易错的规则固定好,把该搜的证据找稳,把每次运行都记账。 |
| 关联知识点 | README 提到 useful without silent degradation、bounded correction、runId 和 delivery artifacts;learn-RAG 08 提供了检索评估框架。 |
OPTIMIZATION优化分层
准确率优化
语义层、schema linking、join path、RAG evidence、SQL validate/correct。
召回优化
metadata、alias、多表示、hybrid、graph、RRF、rerank、gold evidence。
执行优化
planner 路由、dry-run、limit、成本估算、慢查询保护和 read model。
报告优化
data pack cache、chart spec 复用、异步长任务、runId 引用。
成本优化
减少 LLM 轮次、分层模型、上下文压缩、缓存和批量预计算。
观测优化
trace、RAG replay、SQL artifact、错误分类、低置信报警。
DIAGRAM系统优化闭环
从 badcase 到优化发布

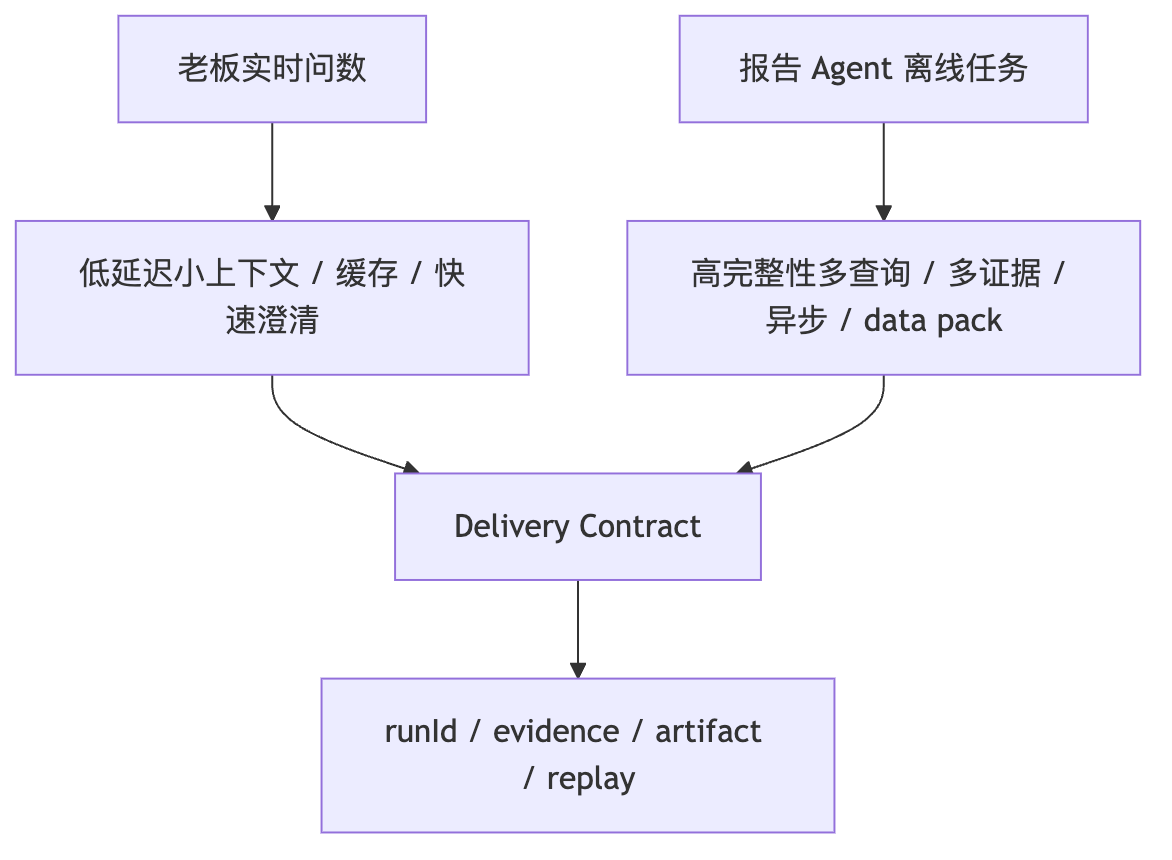
实时问数和报告 Agent 的不同优化
TABLE优化项、指标和收益
| 优化项 | 衡量指标 | 收益 |
|---|---|---|
| RAG hybrid + rerank | Recall@K、MRR、NDCG、Context Recall | 关键证据更完整、更靠前。 |
| Semantic registry | 指标映射准确率、口径错误率 | 减少“SQL 能跑但业务错”。 |
| SQL validation/correction | 执行成功率、安全拒绝率、修复成功率 | 提高可执行性并控制风险。 |
| Entity resolution | 实体消歧准确率、澄清率 | 减少项目和 Token 查错对象。 |
| Planner routing | 工具调用次数、p95 延迟、成本 | 避免每次全工具编排。 |
| Materialized view/cache | 报告生成耗时、DB 扫描量 | 支撑高频报告 Agent 调用。 |
| Observability | 定位时间、回放成功率、错误分类覆盖 | 线上问题更快复盘。 |
优化要用指标说话:召回看 Recall/MRR/NDCG,SQL 看执行和语义准确率,性能看 p95 和成本,可信度看 evidence 完整率和 replay 能力。
ABLATION怎么证明优化有效
| 实验开关 | 看什么指标 | 怎么判断不是“感觉更准” |
|---|---|---|
| baseline | 当前 Recall@K、SQL semantic accuracy、P95、成本 | 所有后续优化都和同一批 gold set、同一权限样本、同一线上分桶比。 |
| + query rewrite | Recall@20、rewrite drift rate、entity preserved rate | 召回提升但实体或时间窗口漂移,不能算成功。 |
| + hybrid retrieval | laneRecall、MRR、NDCG、retrievalP95 | 必须说明收益来自 lexical、dense 还是 graph,不能只报整体分。 |
| + rerank | Recall@5、Context Recall、Context Precision、p95 cost | 证据进 topK 但 p95 翻倍时,只灰度到高价值复杂问题。 |
| + semantic registry | business term mapping accuracy、join path error rate、semantic mismatch rate | 验证“SQL 能跑但业务错”的 badcase 是否下降。 |
| + cache/materialized view | cacheHitRate、staleReadRate、executionP95、policy cache miss | 性能提升不能带来过期读或权限绕过。 |
INTERVIEW MAP面试表达地图
- 先分四条线准确率、可信度、性能、可运维性。
- 再讲具体优化RAG、语义层、SQL、实体解析、planner、缓存、成本、观测。
- 强调评测没有指标的优化只是感觉。
- 区分场景老板实时问数重低延迟,报告 Agent 重完整证据和可引用。
- 收束价值系统从能答变成可证明、可复用、可复盘。
SUBAGENTS面试官和候选人模拟
本章继续沿用第一章的两个 subagent 视角:面试官 subagent 负责追问架构边界、失败模式、评测、治理和下游报告 Agent;候选人 subagent 负责把回答压成现场能讲出来的中文,并且把每个观点落到流程节点、数据对象、合同或工程权衡。
本章追问重点:你的优化是不是只有 prompt?有没有指标、架构改动、性能收益和线上观测?
Q&A20 组高强度追问
面试官:你做的优化是 prompt 优化、检索优化、语义层优化、执行层优化,还是整体架构优化?
我会说是整体架构优化,prompt 只是很小一部分。真正收益来自 RAG evidence、semantic registry、schema linking、SQL validate/correct、planner routing、data pack cache 和 runId observability。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:如何优化 Text2SQL 准确率,同时不牺牲权限、安全和审计?
准确率靠 selected context、semantic-plan、join path 和样例;安全靠权限过滤、只读校验、dry-run 和 fail-closed;审计靠 evidence、artifact 和 runId。不能为了 SQL 成功率绕过治理。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:RAG 召回优化后,怎么证明不是感觉更准?
用固定评测集和 gold evidence 做 ablation。对比 baseline、query rewrite、hybrid、rerank、parent-child 等配置,看 Recall@K、MRR、NDCG、Context Recall、延迟和成本。
RAG 召回质量与 gold evidence 评测:RAG 章主讲召回评测,评测章和优化章用于证明优化不是感觉更准。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:为了支持报告 Agent 高频调用,你做了哪些缓存或物化视图?
常用融资周报、赛道榜单、Token 解锁风险、热度趋势可以预计算或物化;data pack 按任务参数、semanticVersion、权限 scope 和数据版本做缓存,避免每个报告 Agent 重跑全链路。
缓存、物化视图与批量性能:性能章主讲缓存/物化/批量保护,优化章和复杂分析章只补充业务场景。
- 14-performance-cost-concurrency · q02
- 06-optimizations · q08
- 06-optimizations · q14
- 10-complex-analysis-planning · q09
- 10-complex-analysis-planning · q18
- 12-freshness-source-consistency · q02
- 14-performance-cost-concurrency · q03
- 14-performance-cost-concurrency · q04
- 14-performance-cost-concurrency · q07
- 14-performance-cost-concurrency · q13
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:Query Planner 如何避免每次 SQL + RAG + Graph 全部跑一遍?
planner 根据 intent、semantic-plan 和证据需求路由。纯聚合走 SQL,来源解释加 RAG,关系问题加 Graph,趋势问题走 metrics。只有报告型复杂任务才组合多工具。
Query Planner 路由与避免全工具执行:流程章主讲路由判断,优化章主讲降本,复杂分析章主讲计划拆分。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:如何优化实体解析,降低重名导致的错误?
引入别名表、官网域名、社媒 handle、合约地址、链、portfolio、上下文标签等特征。高置信自动解析,低置信澄清,并把消歧证据写入 evidence。
Entity resolution、Token 重名与实体消歧:语义映射章主讲实体解析位置,RAG、优化、澄清和排障章分别补充召回、优化、交互和定位。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:老板实时问数和报告 Agent 离线生成,优化策略有什么不同?
老板实时问数重低延迟和可读答案,适合小上下文、缓存、快速澄清。报告 Agent 重证据完整和可引用,可以异步、多查询、多证据、生成 data pack 并保留 runId。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:成本优化怎么做:LLM token、向量检索、SQL 执行、长报告分别怎么控?
LLM 通过减少轮次、上下文压缩、模型分层控制;检索通过 metadata filter 和 topK 策略控制;SQL 通过 limit、物化视图、dry-run 控制;长报告通过异步、data pack 缓存和增量生成控制。
缓存、物化视图与批量性能:性能章主讲缓存/物化/批量保护,优化章和复杂分析章只补充业务场景。
- 14-performance-cost-concurrency · q02
- 06-optimizations · q04
- 06-optimizations · q14
- 10-complex-analysis-planning · q09
- 10-complex-analysis-planning · q18
- 12-freshness-source-consistency · q02
- 14-performance-cost-concurrency · q03
- 14-performance-cost-concurrency · q04
- 14-performance-cost-concurrency · q07
- 14-performance-cost-concurrency · q13
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:可观测性优化体现在哪里?
每个 run 记录阶段耗时、retrieval hits、selected context、SQL validation、execution summary、degradeReasons、riskTags、delivery artifact。线上按错误分类看召回失败、权限拒绝、SQL 失败、报告引用失败。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:SQL correction 优化如何避免越修越错?
把错误分成 correctable 和 terminal。方言、limit、轻微语法可以修;越权、危险、多语句、核心语义缺证据直接终止。修复次数和 token 预算都要有限。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:你怎么优化空结果体验?
空结果不直接说没有,而是解释可能原因:真实无数据、时间窗口过窄、实体未确认、权限过滤、数据延迟。系统可以给澄清建议或放宽条件的安全选项。
空结果解释、评测与排查:可信结果章主讲空结果怎么可信解释,评测和可观测章分别处理验证与排查。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:如何优化“搜得到但答案没用上”的问题?
这通常不是召回问题,而是上下文装配、排序或生成引用问题。优化 final context、证据排序、引用格式和 answer grounding,同时用 Context Precision/Recall 和 faithfulness 评估。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:如何优化多表 join 的稳定性?
把 join path 从 prompt 抽到 Modeling Layer,维护 relationships 和 cardinality,semantic-plan 锁定路径,validate 检查 SQL 是否偏离授权关系。
Schema linking、schema 变更与 join path:语义映射章主讲 join path,流程和优化章只从生成稳定性角度补充。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:如何优化权限相关性能?
权限不能每次全量计算。可以缓存 workspace datasource binding、table/field permission、agent scope 和 policyVersion,但 delivery 和 execute 前仍要校验版本,避免权限变更后缓存泄漏。
缓存、物化视图与批量性能:性能章主讲缓存/物化/批量保护,优化章和复杂分析章只补充业务场景。
- 14-performance-cost-concurrency · q02
- 06-optimizations · q04
- 06-optimizations · q08
- 10-complex-analysis-planning · q09
- 10-complex-analysis-planning · q18
- 12-freshness-source-consistency · q02
- 14-performance-cost-concurrency · q03
- 14-performance-cost-concurrency · q04
- 14-performance-cost-concurrency · q07
- 14-performance-cost-concurrency · q13
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:如何优化图谱查询成本?
常见关系路径如共同投资、项目-生态、机构 portfolio 可以预计算或限制跳数。planner 只在关系型问题触发 graph,delivery 返回路径证据而不是全图。
GraphRAG、图查询与图数据库:复杂分析章主讲共同投资网络为什么走图,评测、排障和性能章分别补充质量、错误定位和成本。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:如何优化报告 Agent 的数据包复用?
同类报告任务参数相近,可以按 reportType、timeRange、filters、semanticVersion、scope 生成 data pack cache。报告 Agent 可以复用数据和图表规格,再按叙事风格组织文本。
证据链、data pack 与报告可追溯:可信结果章主讲 evidence/data pack 合同,其他章只补充报告 Agent 消费与复用场景。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:如何判断优化是否伤害了安全?
每次优化都要跑权限和安全回归:无权表字段是否被召回,SQL 是否只读,agent scope 是否生效,delivery 是否泄露字段。质量提升不能以绕过治理为代价。
评测、badcase 与回归门禁:评测章主讲体系,优化、安全、观测和性能章只补各自维度的验收。
- 09-evaluation-badcase-loop · q01
- 08-permission-security-governance · q19
- 09-evaluation-badcase-loop · q06
- 09-evaluation-badcase-loop · q09
- 09-evaluation-badcase-loop · q13
- 09-evaluation-badcase-loop · q14
- 09-evaluation-badcase-loop · q18
- 09-evaluation-badcase-loop · q19
- 12-freshness-source-consistency · q19
- 13-observability-troubleshooting · q15
- 13-observability-troubleshooting · q19
- 14-performance-cost-concurrency · q17
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:RAG 索引参数优化怎么做?
先用 FLAT 或高召回配置做对照,再调 HNSW/IVF、topK、metadata index 和 hybrid 权重。关注 Recall@K 和延迟,不要只看平均相似度。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:如何优化用户追问体验?
保留 session、runId、上次 selected context 和语义计划,让追问能复用上下文,但仍要重新检查权限和时间窗口。这样用户可以从“为什么”追到“给我明细”。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
面试官:面试里一句话总结你的优化,你怎么说?
我会说:我不是单点调 prompt,而是围绕证据、语义、执行、交付和观测做系统优化,让 Agent Bot 从能回答升级为可证明、可复用、可回放的数据智能层。
理解与记忆 · 背后工程点
背后工程点:优化要覆盖准确率、召回、执行安全、成本、延迟、缓存和可观测性,不能只讲 prompt。
专业术语:Ablation 是逐项开关优化手段来确认收益;Materialized View 是预计算常用聚合以降低查询成本;Observability 是用 trace、指标和错误分类看系统健康度。
为什么这样回答:这样回答能体现生产级系统优化是多目标权衡。
小白解析:优化不是只让答案看起来更聪明,还要更稳、更快、更便宜、更容易排查。
关联知识点:text2sql 强调 bounded correction、evidence、artifact、runId;learn-RAG 强调用评估闭环驱动优化。
PRINCIPLE本章背诵原则
- 优化要分层:准确率、可信度、性能、成本、可观测性都要讲。
- 指标说话:RAG 用 Recall/MRR/NDCG,SQL 用语义准确率和执行成功率,性能用 p95 和成本。
- 别牺牲治理:任何准确率优化都不能绕过权限、安全和审计。
- 场景不同:老板实时问数和报告 Agent 离线生成的优化目标不同。
- 闭环迭代:badcase -> 分类 -> 优化 -> 评测 -> 发布 -> 监控。