OPENING30 秒开口版
我会把语义层设计成物理表结构和业务语言之间的稳定抽象。用户说“未 TGE”,系统映射到 token_status、tge_date 和 Token 发行状态;说“融资强”,系统映射到融资金额、轮次、投资人质量和时间窗口;说“热度上涨”,系统映射到 score_snapshots 的变化率。Text2SQL 生成前必须先锁定 semanticVersion、metric definition、relationship path 和默认口径,口径冲突时澄清或 fail-closed。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。 Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。 Semantic Version:语义口径版本,用来支持回放、审计和发布。 Relationship Path:表与表之间经过治理的 Join 或图关系路径。 |
| 为什么这样回答 | 语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。 |
| 小白解析 | 语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。 |
| 关联知识点 | Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。 |
1 MIN一分钟口语版
语义层的价值是把 Join、计算公式、指标解释和默认过滤从 prompt 里拿出来,变成可版本化、可审计、可评测的配置。它包含 Models、Metrics、Dimensions、Calculated Fields、Relationships、Glossary 和别名映射。RAG 负责召回相关语义资产,assemble-context 把它整理成 context pack,semantic-plan 用它决定 selectedTables、selectedColumns、join path、filters 和 route constraints。下游报告 Agent 拿到 data pack 时,也会看到 semanticVersion 和指标说明,保证老板端、投研端和报告端说的是同一套口径。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。 Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。 Semantic Version:语义口径版本,用来支持回放、审计和发布。 Relationship Path:表与表之间经过治理的 Join 或图关系路径。 |
| 为什么这样回答 | 语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。 |
| 小白解析 | 语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。 |
| 关联知识点 | Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。 |
ARCHITECTURE架构设计要点
业务词典
收敛未 TGE、融资强、顶级投资人、热度上涨等业务说法。
指标定义
计算公式、时间窗口、默认过滤、排序规则、解释文案。
关系路径
项目、Token、融资、机构、人物、生态的 join path 和图路径。
版本治理
semanticVersion 支持灰度、回滚、历史 runId 回放。
RAG 联动
语义资产进入索引,retrieve 和 assemble-context 召回可执行指令。
报告复用
data pack 暴露指标口径,让报告 Agent 不重新解释。
DIAGRAM架构图
语义层连接业务语言和物理表

指标版本如何支持回放
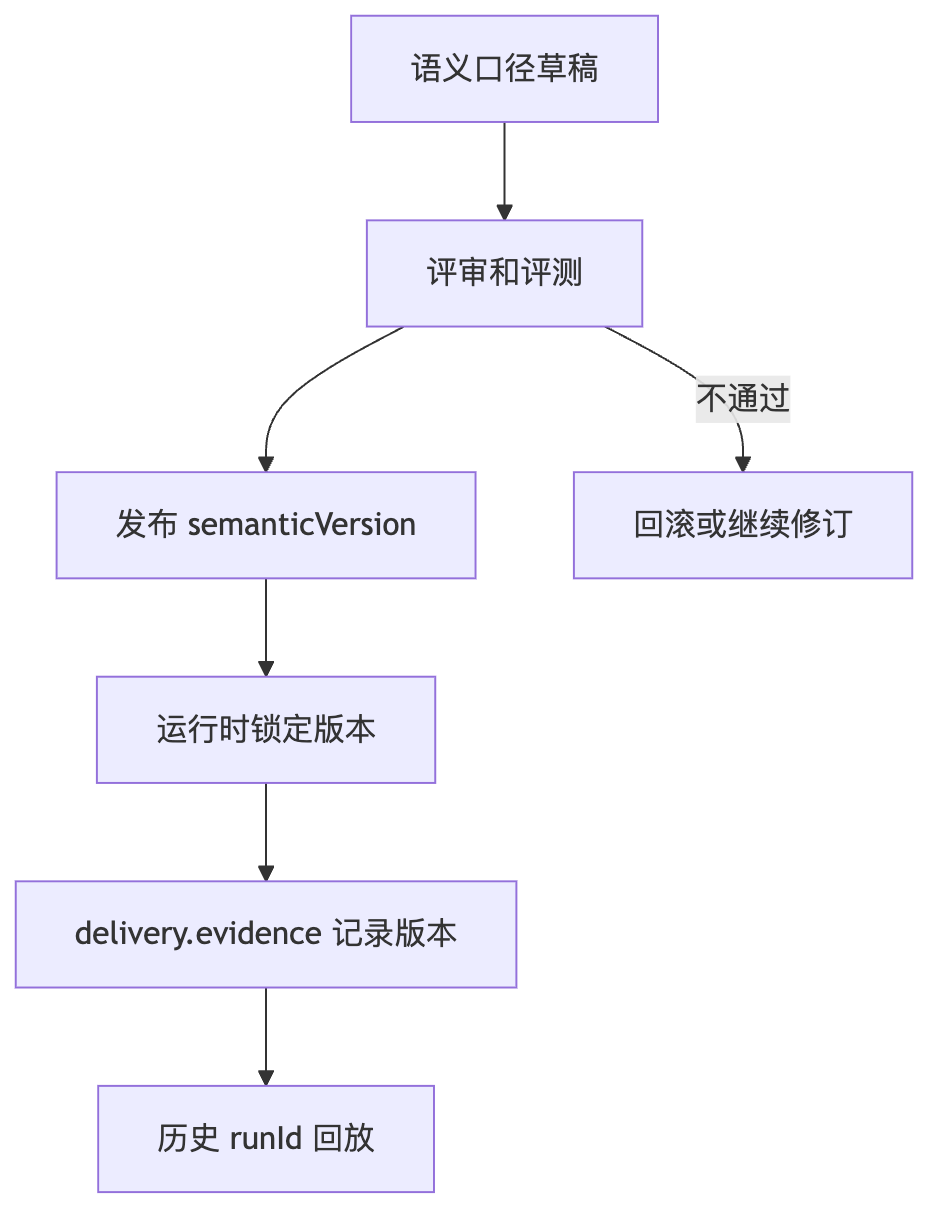
TABLE关键对象和面试讲法
| 对象 | 职责 | 面试强调 |
|---|---|---|
| 未 TGE | tokens.token_status、tge_date | Token 状态和日期冲突要标风险。 |
| 融资强 | amount_usd、round、lead investor、time window | 不是单一金额字段。 |
| 顶级投资人 | organization tier、历史投资表现、lead 关系 | 需要机构语义和图关系。 |
| 热度上涨 | score_snapshots 变化率 | 必须有默认窗口和基准点。 |
| 透明度低 | 字段完整度、团队、Token、融资披露 | 解释缺失项比只给分更重要。 |
| 解锁压力 | unlock amount、供应占比、未来窗口 | 结合 Token 和市场数据。 |
| AI x Crypto | tags、project_tags、文本证据 | 标签和 RAG 证据共同判断。 |
VERSIONINGsemanticVersion 生命周期
| 阶段 | 要做什么 | 面试追问时的答法 |
|---|---|---|
| draft | 业务方提出指标变更,写明公式、字段、时间窗口、默认排序和适用场景。 | 临时规则不能直接写 production semantic registry,避免语义资产污染。 |
| review | 检查 join path、权限影响、历史报告兼容、gold set 变化。 | 语义层变更不是文案变更,会影响 SQL、报告和回放。 |
| shadow eval | 用新旧 semanticVersion 跑同一批 gold questions 和线上 sample。 | 看 semantic accuracy、join path error、citation accuracy、结果分布变化。 |
| gray release | 按 workspace、报告类型或问题分桶灰度,并把 semanticVersion 写入 runId 和 data pack。 | 报告 Agent 必须知道本次报告用了哪个指标版本。 |
| rollback | 新版本 badcase 升高时回退 active version;历史 run 保留原版本。 | 回滚不能改写历史 runId,只能影响新请求。 |
INTERVIEW MAP面试表达地图
- 先讲问题业务词不稳定会导致 SQL 能跑但业务错。
- 再讲结构glossary、registry、metric、dimension、relationship、version。
- 落到例子未 TGE、融资强、热度上涨、解锁压力。
- 连接流程retrieve -> assemble-context -> semantic-plan -> generate-sql。
- 收束治理版本、评测、回滚、报告复用。
SUBAGENTS面试官、候选人和红队
本章写作前已实际启动多 subagent:面试官 subagent 负责连续追问生产压力,候选人 subagent 负责把答案压成现场能讲出口的表达,资料审阅 + 红队 subagent 负责指出哪些地方容易写虚,并补充安全、评测、runId、下游报告 Agent 的攻击面。
本章追问重点:所有回答都要落到 RootData 类 Web3 主项目、Agent Bot、Text2SQL、RAG、runId/evidence/artifact/data pack 和下游报告 Agent 复用。
Q&A20 组高强度追问
面试官:“融资强”到底是什么?
我:不能让模型临场猜。我会把它定义成可配置指标,默认包括近 30 天融资金额、轮次权重、lead investor 质量和投资机构数量。不同场景可以切口径,但必须有 semanticVersion。
业务语义、模糊词与默认口径:语义映射章主讲业务词如何落表,语义层和澄清章主讲默认与追问边界。
理解与记忆 · 背后工程点
背后工程点:业务词要变成指标定义。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:“未 TGE”对应哪些表字段?
我:主要看 tokens.token_status、tge_date、token launch 事件,也可能看项目详情里的 Token 状态来源。状态和日期冲突时,answer 要标记 conflictHint。
理解与记忆 · 背后工程点
背后工程点:业务状态可能跨结构化字段和来源证据。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:“热度上涨”用 24h、7d 还是 30d?
我:默认口径要在 semantic registry 里,比如老板实时看 7d,周报用 30d。用户没指定时使用 smart default 并在 answer 说明,影响结果很大时触发澄清。
业务语义、模糊词与默认口径:语义映射章主讲业务词如何落表,语义层和澄清章主讲默认与追问边界。
理解与记忆 · 背后工程点
背后工程点:时间窗口是指标口径的一部分。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:semantic-plan 如何使用语义层?
我:retrieve 召回相关 metric、dimension、relationship 和 examples,assemble-context 生成结构化 context pack,semantic-plan 输出 selectedTables、selectedColumns、filters、joinPaths、metricFormula 和 route constraints。
理解与记忆 · 背后工程点
背后工程点:语义层要进入结构化计划,而不是塞一段文本。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:指标口径升级后,历史 runId 怎么回放?
我:历史 runId 记录 semanticVersion 和 metric definition refs。回放时按当时版本解释结果;如果用新版本重算,要生成新的 runId 并标注口径变化。
Semantic version 与指标口径回放:语义层主讲口径版本锁,架构和时效章补充 runId 回放与历史报告。
理解与记忆 · 背后工程点
背后工程点:版本锁定是可回放的前提。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:报告 Agent 如何知道本次报告使用哪个口径?
我:data pack 中包含 semanticVersion、metric definitions、timeWindow、filters 和 evidenceRefs。报告 Agent 输出图表和结论时必须带这些引用。
Semantic version 与指标口径回放:语义层主讲口径版本锁,架构和时效章补充 runId 回放与历史报告。
理解与记忆 · 背后工程点
背后工程点:报告复用必须携带指标元数据。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:同义词、别名、Token symbol 怎么进入语义层?
我:通过 glossary 和 entity resolution 管理 alias、slug、symbol、contract address、官网和社媒。候选实体低置信时不能直接绑定 SQL,要澄清或返回候选。
理解与记忆 · 背后工程点
背后工程点:别名治理连接自然语言和实体主数据。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:“透明度低”如何解释给用户?
我:不能只给分,要展示分项:基础信息缺失、团队信息缺失、Token 经济缺失、融资来源缺失、日历事件缺失。每个分项对应字段和来源。
理解与记忆 · 背后工程点
背后工程点:评分指标要可解释。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:业务方临时改评分权重,如何防止线上漂移?
我:新权重先作为 draft semanticVersion,跑评测和灰度,通过后发布。运行时锁定版本,报告 Agent 也记录版本,不能直接热改线上口径。
理解与记忆 · 背后工程点
背后工程点:指标变更需要版本发布流程。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:schema 变更后语义层如何更新?
我:元数据订阅或重建任务检测表列变化,更新 schema graph 和 semantic bindings,重新索引语义资产,并跑 schema linking 和关键问题回归。
Schema linking、schema 变更与 join path:语义映射章主讲 join path,流程和优化章只从生成稳定性角度补充。
理解与记忆 · 背后工程点
背后工程点:语义层要跟 schema 生命周期联动。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:语义层和 RAG schema 检索是什么关系?
我:RAG 负责找候选语义资产和 schema 证据,语义层提供权威口径和关系路径。retrieve 找材料,semantic-plan 决定如何使用材料。
理解与记忆 · 背后工程点
背后工程点:RAG 是召回,语义层是治理口径。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:Join path 幻觉怎么解决?
我:预定义 relationships 和 relationship graph,Planner 从候选路径里选择,不允许 LLM 自己发明 join key。validate 还会检查字段存在和关系路径是否允许。
Schema linking、schema 变更与 join path:语义映射章主讲 join path,流程和优化章只从生成稳定性角度补充。
理解与记忆 · 背后工程点
背后工程点:Join 路径必须被建模。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:复杂计算字段怎么处理?
我:把环比、同比、解锁占比、融资强度这类公式作为 calculated fields 或 metric definition。LLM 调用语义对象,不临时写复杂公式。
理解与记忆 · 背后工程点
背后工程点:复杂计算要下沉到配置层。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:如果语义层没有覆盖用户说法怎么办?
我:先通过 RAG 和 glossary 找候选,低置信时澄清或返回“口径未确认”。高价值新术语可以进入 candidate memory,人工验证后再晋升。
业务语义、模糊词与默认口径:语义映射章主讲业务词如何落表,语义层和澄清章主讲默认与追问边界。
理解与记忆 · 背后工程点
背后工程点:语义缺口要治理,不能让模型随便补。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:如何防止语义资产污染?
我:candidate -> verified -> production 分级晋升,记录来源 runId、审核人、适用域和 TTL。线上只默认使用 verified 或 production,不让临时记忆直接影响核心指标。
理解与记忆 · 背后工程点
背后工程点:语义记忆要有晋升流程。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:不同团队指标口径不同怎么办?
我:按 workspace 或 domain 维护语义版本和 override,但公共报告要显式声明使用哪个 workspace/domain 口径。跨团队比较时要先对齐口径。
理解与记忆 · 背后工程点
背后工程点:口径可以多版本,但必须显式。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:如何评测语义层效果?
我:看 schema linking 准确率、metric binding 稳定率、SQL 语义正确率、同义词召回、复杂问题成功率,以及口径变更后的回归结果。
理解与记忆 · 背后工程点
背后工程点:语义层也要可量化。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:语义层会不会增加维护成本?
我:会,但它把成本从每次 prompt 纠错转成集中治理。对于融资、Token、评分这些高价值领域,稳定口径带来的准确率和可审计性更值得。
理解与记忆 · 背后工程点
背后工程点:要承认成本并说明收益。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:什么时候需要澄清而不是用默认语义?
我:当多个口径都合理且结果差异大时,比如“融资好”按金额还是顶级投资人,或者“最近”是 7d 还是季度。低风险默认可以执行并声明默认值。
业务语义、模糊词与默认口径:语义映射章主讲业务词如何落表,语义层和澄清章主讲默认与追问边界。
理解与记忆 · 背后工程点
背后工程点:语义层和澄清策略要配合。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
面试官:一句话总结语义层设计。
我:语义层的目标是让业务词、指标口径、表结构和关系路径成为可版本化事实,而不是每次让模型重新发明。
理解与记忆 · 背后工程点
背后工程点:总结要强调稳定和版本化。
专业术语:Semantic Registry:集中管理业务术语、指标、维度、关系和版本的语义注册表。
Metric Definition:指标的计算公式、过滤条件、时间窗口和解释。
Semantic Version:语义口径版本,用来支持回放、审计和发布。
为什么这样回答:语义层题要从具体业务词切入,避免抽象说“统一口径”。面试官想听你如何把自然语言、表结构和指标版本连起来。
小白解析:语义层就像一本公司内部指标字典。大家说“热度上涨”时,系统知道看哪张表、怎么算、用几天窗口,而不是每次都让模型自己猜。
关联知识点:Modeling Layer 文档把 MDL 定义为物理 schema 和业务语言之间的抽象层,核心组件包括 Models、Calculated Fields、Relationships、Metrics、Dimensions。text2sql 当前实现有 semantic spine、workspace modeling 和 relationship graph。
PRINCIPLE本章背诵原则
- 业务词必须沉淀成语义对象。
- 指标口径要有版本、解释和评测。
- Join、公式、默认窗口不要交给模型猜。
- 语义层和 RAG 是召回与治理的关系。
- 历史 runId 必须能按当时 semanticVersion 回放。