OPENING30 秒开口版
我会把这个项目介绍成一个接在 RootData 类 Web3 资产情报平台上的 Query OS / 数据智能层。主项目负责生产和维护项目、机构、人物、融资、Token、解锁、新闻、评分、关系图谱这些事实源;Agent Bot 不把 Text2SQL 做成“LLM 直接写 SQL”,而是把老板、投研和下游报告 Agent 的问题,编译成带权限边界、语义计划、SQL 校验、执行证据和 runId 回放的查询运行。它输出的不只是 answer,还包括 evidence、artifact、chart spec、data pack 和 replay 线索。这个设计的核心是:SQL 是一次可执行编译产物,事实源、权限、语义和验证都由系统掌控。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Query OS:把用户意图、schema、语义、权限、计划、SQL、执行结果和回放证据编译成一次可信问数运行的系统。 Source of Truth:schema catalog、metric definition、policy、source document、execution trace 这些可审计事实源。 Selected Context:经过检索、权限过滤和预算控制后允许模型看到的上下文。 Delivery Contract:系统对前端和下游 Agent 输出的统一结构,包含 answer、evidence、artifact、data pack 和 runId。 RunId:一次问答或分析运行的追踪标识,用于审计、回放和报告引用。 |
| 为什么这样回答 | 第一章要抢的是“架构设计”的定义权,所以开口先把 Text2SQL 从 prompt demo 提升为 Query OS:主项目生产事实,Agent Bot 编译和治理事实,下游报告 Agent 消费受控数据包。这样面试官会把注意力放在事实源、权限、计划、验证和交付契约,而不是只追问模型怎么写 SQL。 |
| 小白解析 | 主项目像 Web3 资产数据工厂,Agent Bot 像带质检的查询操作台。它先确认哪些数据是真的、当前用户能看什么、业务词对应什么口径,再决定怎么查和怎么交付。 |
| 关联知识点 | RootData 类主项目强调结构化数据、搜索、关系图谱、来源留痕、API 商业化和字段权限。新的 Text2SQL 范式强调 SQL 是编译产物,不是事实源;Prompt 只是 selected context 的一次性视图;最终回答必须忠于 rows、columns、SQL 和 evidence。 |
1 MIN一分钟口语版
如果展开讲,我会按 Query OS 的八个平面讲。Governance Plane 先确定 actor、workspace、datasource binding、table/column ACL 和 agent scope;Knowledge Plane 管 schema catalog、字段注释、关系、样例和来源文档;Semantic Plane 管 glossary、metric definition、calculated field、join path 和 semanticVersion;Intent Plane 把问题抽成 QuerySlots,判断是否需要澄清;Planning Plane 生成 IntentPlan、SemanticPlan 和 PhysicalSqlPlan;Compilation Plane 把授权后的 schema、指标、关系和样例编译成 selected context 和结构化 SQL 生成约束;Validation Plane 做 plan check、AST、readonly、ACL、limit、dry-run 和有界 correct loop;Execution & Feedback Plane 执行查询,把 rows/columns 格式化成 grounded answer,并持久化 replay 和评测样例。这样设计的好处是:主项目事实源不被聊天逻辑污染,模型看不到未授权 schema,SQL 受计划和校验约束,下游报告 Agent 只消费可引用、可回放的数据包。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Schema Catalog:版本化的表、列、类型、注释、样例值和关系事实。 Metric Definition:稳定指标口径,避免模型现场发明公式。 QuerySlots:问题类型、指标、维度、过滤、时间范围和歧义的结构化投影。 PhysicalSqlPlan:SQL 生成前的表、列、join、聚合、过滤、排序和 limit 合同。 Text2SqlReplay:按 runId 重建 selected context、plans、SQL、validation、execution 和 answer 的证据账本。 |
| 为什么这样回答 | 一分钟版直接按 Query OS 平面讲,能体现你知道准确率来自上下文、语义、计划、验证和反馈的系统能力,而不是单点 LLM 能力。 |
| 小白解析 | 这套架构像把数据平台改造成可对话的查询系统:先建数据目录和口径手册,再让调度台按权限挑资料、定查询计划、写 SQL、质检、交付。 |
| 关联知识点 | text2sql README 里后端拆成 conversation、knowledge、governance、platform;主链路是 Text2SQLWorkflowRunner -> RunV2LangGraphStage -> Text2SqlV2LangGraphRunnerService。新范式进一步把这些节点解释成 Source of Truth、State Projection、Query Compiler、Validator/Executor、Grounded Answer 和 Replay/Eval 的分层。 |
DESIGN GOALS第一章先讲架构目标
事实源和上下文分离
schema catalog、semantic registry、policy、source documents 是事实源;prompt 只是本轮 selected context 的编译结果。
同时服务人和 Agent
老板、投研通过 Bot 问数据;融资周报、赛道分析、尽调报告等下游报告 Agent 通过工具接口拿数据包。
统一 Web3 业务语义
未 TGE、融资强、解锁压力、顶级投资人、热度上涨等口径不能靠模型临场解释,要沉到 metric definition 和 semantic registry。
组合多种查询引擎
结构化事实走 SQL,项目名和新闻走搜索,机构共投和生态路径走图查询,热度和 Token 指标走时间序列。
治理覆盖全链路
权限不是只在 SQL 执行前判断,prompt 前的 RAG 检索、selected context、SQL、图查询、data pack 都要受用户和 Agent scope 约束。
交付必须可引用可回放
输出不只是自然语言答案,还要有 evidence、artifact、chart spec、data pack、runId,方便报告引用、审计和 replay。
ARCHAgent Bot 架构分层
从主项目数据到人类和下游 Agent 的依赖方向
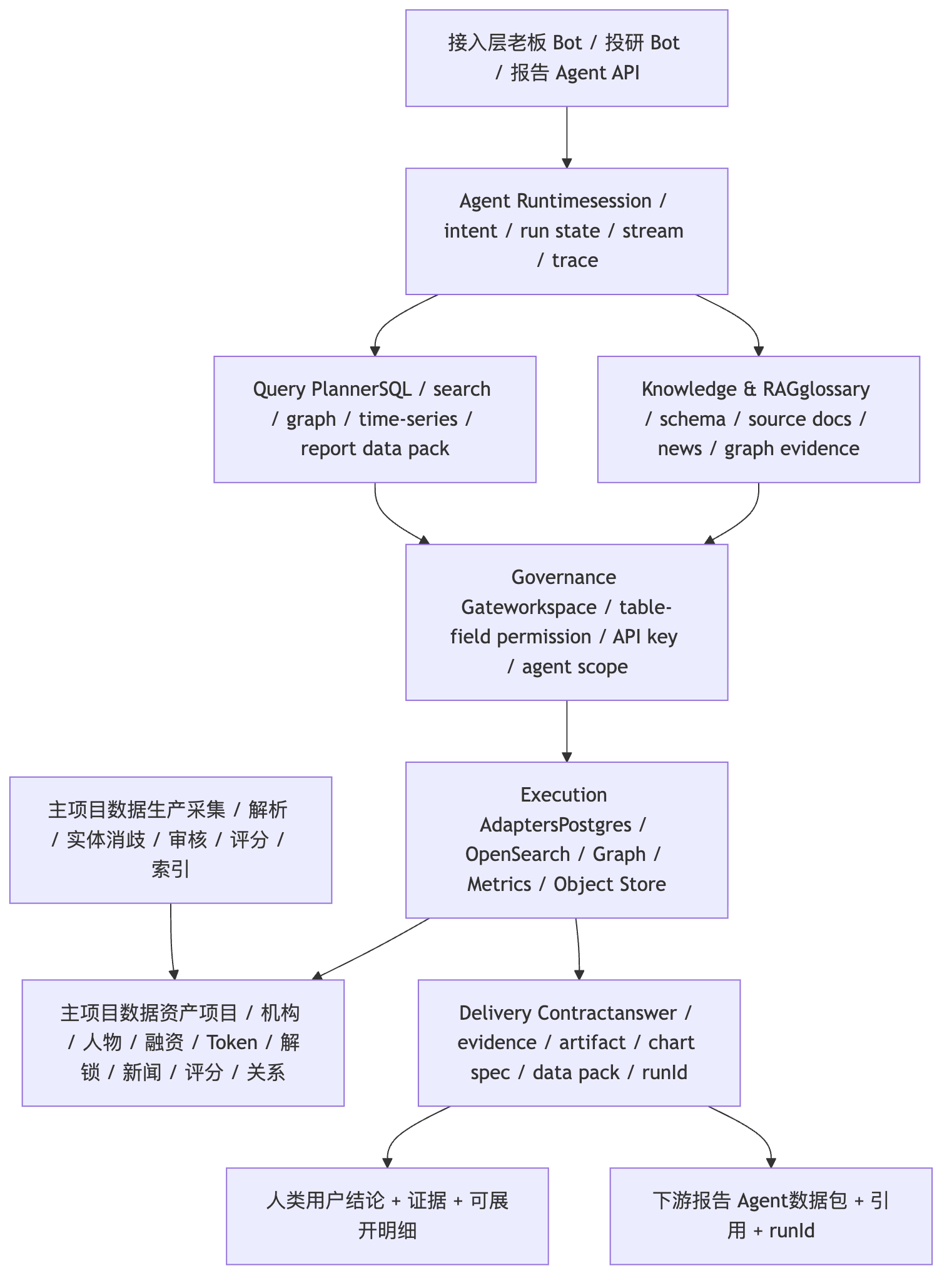
| 架构层 | 核心职责 | 关键设计点 |
|---|---|---|
| 主项目数据生产层 | 采集、解析、实体消歧、审核、评分、索引、来源留痕。 | Agent Bot 不重做数据生产,只消费主项目沉淀的可信事实。 |
| 主项目数据资产层 | Postgres 主库、OpenSearch、关系图谱、时序快照、source_documents、对象存储。 | 不同问题走不同事实源,不能把所有能力压成一条 SQL。 |
| Agent 接入层 | 老板 Bot、内部投研 Bot、数据运营工作台、下游报告 Agent API。 | 统一入口但区分 identity、workspace、API key、agent scope 和输出格式。 |
| Agent Runtime 层 | session、intent routing、run state、stream/sync、tool scheduling、trace。 | Runtime 只编排流程,不直接拥有 RAG 索引、权限规则和业务指标口径。 |
| Knowledge / Semantic 层 | schema catalog、glossary、metric definition、semantic registry、source evidence、historical examples、graph evidence。 | 这是模型写 SQL 前的事实和语义资产,不是一次性 prompt 文本。 |
| Planning / Compilation 层 | QuerySlots、IntentPlan、SemanticPlan、PhysicalSqlPlan、selected context、structured SQL output。 | 先让计划约束 SQL,再让模型在授权上下文里生成结构化草案。 |
| Validation / Execution 层 | plan validation、AST、readonly、single statement、schema/ACL check、limit、dry-run、correct loop、query executor。 | SQL 是草案,验证通过后才是可执行查询;安全拒绝和可修复错误要分开。 |
| Delivery / Feedback 层 | grounded answer、evidence、artifact、chart spec、data pack、runId、audit、replay、eval case。 | 同一次运行既能给人看,也能被报告 Agent 引用,并能沉淀为回归评测资产。 |
面试时这张图的关键不是层数多,而是依赖方向清楚:主项目负责事实生产,Agent Runtime 负责编排,knowledge 和 semantic model 提供可审计事实,planner/compiler 把问题变成可验证计划和 selected context,validator/executor 负责安全执行,delivery/replay 让人和下游报告 Agent 都能消费同一份可信结果。
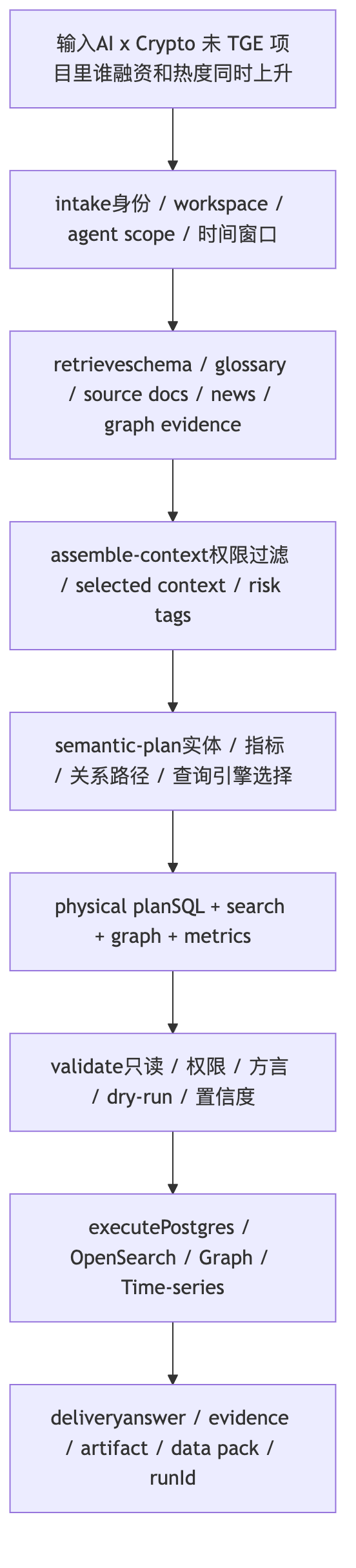
RUNTIME FLOW运行时架构链路
一个 Web3 投研问题在运行时如何流动
KNOWLEDGE ARCH知识与查询编排层
| 知识/执行资产 | 架构职责 | 为什么不能省 |
|---|---|---|
| Schema / Modeling Layer | 定义表、字段、关系、指标、维度和 semanticVersion。 | 让“融资强”“未 TGE”“热度上涨”有稳定可执行口径。 |
| Glossary / 术语库 | 解释 Web3 投研词汇、缩写、别名和业务判断规则。 | 用户不会说表名字段名,系统必须能理解业务语言。 |
| Source Documents / News | 保存官方公告、新闻、研究材料、字段来源和可靠性评分。 | 报告 Agent 需要引用来源,老板也需要知道结论可不可信。 |
| Entity Resolution / Graph | 处理项目别名、Token 符号重复、机构别名、多跳投资关系和生态关系。 | Web3 实体变化快、同名多、关系复杂,只靠关键词会搜错对象。 |
| Query Executors | Postgres、OpenSearch、图查询、时序查询、对象存储各自执行事实查询。 | 一个投研问题通常同时需要结构化统计、证据文档、关系路径和趋势指标。 |
这里的 RAG 不是“向量库里找几段文本”,而是知识与执行编排的一部分:它先帮助系统找到 schema、术语、来源、关系和历史样例,再由 semantic-plan 决定该走 SQL、搜索、图查询还是组合计划。
INTERVIEW MAP面试表达地图
- 先定总范式Text2SQL 是 Query OS:把事实源、语义资产、权限、计划、SQL、执行结果和回放证据编译成一次问数运行。
- 再讲依赖方向主项目负责事实生产,Agent Bot 负责查询编译和治理,下游报告 Agent 只消费受控数据包。
- 然后讲八个平面Governance、Knowledge、Semantic、Intent、Planning、Compilation、Validation、Execution/Feedback。
- 接着讲运行时链路active schema catalog、ACL-filtered selected context、semantic/physical plan、structured SQL、validation、execute、grounded answer、replay。
- 最后讲演进和坑从 prompt + SQL demo 升级到受治理、可验证、可回放的 Query OS,代价是边界、评测和观测复杂度上升。
SENIOR DEFENSE已落地和演进边界
| 层级 | 面试时可以说已落地的口径 | 应该诚实说成演进设计的口径 |
|---|---|---|
| 运行时主链 | intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer 的主叙事和 runId 串联。 | 更细的多 Agent 编排、跨报告任务长期记忆、复杂队列优先级可以说是后续增强。 |
| RAG / 证据 | schema、glossary、source_documents、历史样例、selected context、基础 gold evidence 评测。 | 完整 RagReplay、lane-level ablation、query rewrite drift 自动门禁可以说是系统化升级。 |
| 治理安全 | workspace、datasource binding、table/field permission、只读 SQL、AST validation、fail-closed。 | 跨 run 推断攻击检测、细粒度差分查询防护、完整外部报告合规模型可以说是高级防线。 |
| 可信交付 | answer、evidence、artifact、data pack、source runId、semanticVersion / policyVersion 写入交付合同。 | 半年后报告全链路审计、旧模板自动兼容和多版本 contract migration 可以说是演进方向。 |
| 评测门禁 | gold evidence、gold SQL / expected result、badcase 回流、发布前回归。 | 严格数值阈值、自动阻断发布、全量 SLO 看板可以按团队成熟度说明。 |
如果被问“这是你实际做过还是面试总结”,不要硬装全量生产化。更好的 senior 说法是:我会区分已落地能力和架构演进,已落地保证主链、治理、证据和回放可用,演进设计解决规模化报告 Agent、自动门禁和高级安全攻击面。
SUBAGENTS面试官和候选人模拟
本章按两个 subagent 角色收敛:面试官 subagent 主要追问架构设计有没有边界、有没有依赖方向、有没有治理、有没有可复用交付合同;候选人 subagent 把答案压成面试现场能讲出口的架构表达,每个回答都落到层、接口、数据流、失败模式或权衡。
下面 20 组 Q&A 全部改成架构设计追问。业务背景只作为例子出现,重点回答“为什么这么分层、怎么连接、哪里治理、如何演进”。
Q&A20 组架构设计追问
面试官:从架构设计上看,为什么要把 Agent Bot 做成独立的数据智能层,而不是把问答逻辑直接塞进主项目 service?第二层追问:搜索页、API、SQL 已经存在,为什么还需要这一层?
我会说,搜索页解决人工浏览,API 解决程序取数,SQL 解决结构化查询,但老板和报告 Agent 要的是“带业务解释、来源证据、权限边界和可回放证据的数据结论”。所以我不会把问答逻辑塞进主项目 service,也不会让模型直接拼 SQL。Agent Bot 更像 Query OS:先从主项目拿 active schema catalog、metric definition、source documents 和 policy,再按 actor/workspace 裁剪 selected context,生成 QuerySlots、SemanticPlan 和 PhysicalSqlPlan,最后把 SQL 草案经过 AST、readonly、ACL、dry-run 和 correct loop 变成可执行查询。这样主项目还是事实源,Agent Bot 是查询编译和治理层,下游报告 Agent 只拿受控 data pack 和 runId。
理解与记忆 · 背后工程点
背后工程点:主项目 Agent Bot 的核心是可信查询编译,不是 SQL 字符串生成。
专业术语:
Query OS 是受事实、语义、权限、计划、验证和回放约束的问数系统;
Data Pack 是给人或报告 Agent 消费的数据包;
Governed Execution 是受权限和安全策略约束的执行;
Replay 是按 runId 回看 selected context、plans、SQL、validation 和 answer。
为什么这样回答:先把搜索页、API、SQL 的边界讲清,再解释 Agent Bot 为什么是系统层能力。
小白解析:API 像仓库取货口,Agent Bot 像带质检的查询操作台,不只拿货,还会确认货从哪来、谁能看、口径是什么、结果能不能复查。
关联知识点:主项目文档强调 API、结构化数据库、关系图谱和可信评分;新 Text2SQL 范式强调 Source of Truth、SelectedContextPack、Plan Validation、Grounded Answer 和 Text2SqlReplay。
面试官:你的后端为什么按 conversation、knowledge、governance、platform 拆能力域?第二层追问:这些域和主项目的数据生产、搜索索引、开放 API 怎么解耦?
我会把它们解释成 Agent Bot 子系统的边界,而不是替代主项目。主项目负责生产和维护 Web3 资产数据,Agent Bot 负责基于这些数据回答问题。conversation 承接老板和报告 Agent 的请求;knowledge 把 Web3 术语、来源文档、图谱和 schema 变成证据;governance 控制人和下游 Agent 的权限;platform/execution 负责查询、缓存、持久化和观测。这样 Agent Bot 可以站在主项目之上复用数据资产,而不是再造一套数据平台。
理解与记忆 · 背后工程点
背后工程点:能力域拆分是为了依赖方向和风险隔离。
专业术语:
Capability Domain 是按业务能力划分的模块边界;
Dependency Direction 是模块依赖方向;
God Service 是承载过多职责的上帝服务;
Facade Contract 是跨域调用的稳定接口。
为什么这样回答:不要只说“模块清晰”,要讲失控场景。
小白解析:餐厅里点餐、后厨、收银、仓库如果全由一个人管,出了问题不知道谁负责。
关联知识点:README 明确四大能力域和依赖方向;business-logic 提到 KnowledgeFacade 用 contract-first 收口 conversation 到 knowledge 的调用。
面试官:Agent Runtime / conversation 层在架构里到底负责什么?第二层追问:为什么它只做编排,不直接拥有 RAG 索引、权限判断和业务指标口径?
conversation 是问答主链路,它负责从 session message 到 Text2SQL workflow,再到 delivery contract。它要知道当前 run 走到 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、execute、answer 哪一步,但不应该自己实现 RAG 索引,也不应该自己决定表权限或指标公式。RAG 属于 knowledge,权限属于 governance,指标口径属于 semantic model,SQL 解析和 dry-run 属于 validator/executor。conversation 只编排这些 facade 的结构化合同,这样 ChatService 不会变成上帝对象。
理解与记忆 · 背后工程点
背后工程点:编排层要薄,复杂规则留在专业域。
专业术语:
Orchestration 是流程编排;
Domain Service 是负责特定业务能力的服务;
Contract Boundary 是模块之间稳定交换的数据结构;
Delivery Mapper 是把运行结果映射成交付合同的组件。
为什么这样回答:面试官在测你是否懂边界,不只是会画图。
小白解析:主持人负责串流程,不负责亲自做饭、验钞、搬货。
关联知识点:text2sql 主链固定为 Text2SQLWorkflowRunner -> RunV2LangGraphStage -> Text2SqlV2LangGraphRunnerService;knowledge 通过 facade 提供 rag、glossary、semanticRegistry、memory。
面试官:Knowledge / Semantic 层在这套架构里解决什么问题?第二层追问:如果只把数据库 schema 丢给 LLM,会在哪些 Web3 场景失败?
schema 只告诉系统 projects、funding_rounds、tokens 这些表长什么样,但老板和投研说的是“未 TGE、融资强、顶级投资人、解锁压力、AI x Crypto、透明度低”。knowledge 域补的是这些 Web3 业务语义:术语、指标定义、source_documents、新闻证据、semantic spine、relationship graph、历史查询样例。没有它,模型只能看到字段名,无法稳定理解项目基本面、共投网络、融资趋势和风险证据。
理解与记忆 · 背后工程点
背后工程点:knowledge 是 Web3 投研语言到主项目数据资产的桥。
专业术语:
Schema Linking 是把问题实体连接到表和列;
Glossary Term 是业务术语;
Source Evidence 是字段来源和新闻公告证据;
Relationship Graph 是项目、机构、人物、生态、Token 的关系图。
为什么这样回答:用 Web3 术语举例,避免答案还停留在泛企业问数。
小白解析:数据库只写着很多表名,knowledge 负责告诉系统“未 TGE”和“顶级投资人”到底该查哪里。
关联知识点:主项目文档强调实体关系图谱、来源留痕、评分指标和 API;RAG v2.0 强调从内容检索升级为语义建模与知识推理。
面试官:Governance 层为什么必须覆盖人类用户、API key 和下游报告 Agent?第二层追问:报告 Agent 是内部能力,为什么架构上仍然不能让它直连数据库?
因为报告 Agent 生成的是对外可传播的内容,一旦它绕过系统 Agent 直接查库,就可能拿到未审核字段、超套餐字段、低置信来源或不该展示的内部数据。governance 要统一控制老板、投研、普通用户、API 客户和下游 Agent 的 scope。RAG 检索、SQL 执行、source evidence 和 data pack 都要在授权范围内生成。这样报告 Agent 只负责组织报告,不负责决定哪些数据能用。
系统 Agent 与报告 Agent 边界:主讲系统 Agent 为什么统一出 data pack,其他题只补权限、性能或踩坑角度。
理解与记忆 · 背后工程点
背后工程点:权限既影响执行,也影响报告 Agent 能拿到的证据包。
专业术语:
Agent Scope 是下游 Agent 被允许访问的数据范围;
Field-level Permission 是字段级可见性;
Default Deny 是默认拒绝;
Audit Trail 是权限和调用审计链。
为什么这样回答:把报告 Agent 当成一类调用方,而不是可信万能后门。
小白解析:写报告的助手也不能随便翻老板抽屉,它只能拿系统允许它看的资料。
关联知识点:主项目 API 商业化需要 API Key、配额、字段权限和用量日志;text2sql 治理模型强调权限不确定时 fail-closed。
面试官:Platform / Execution 层在架构里承担什么抽象?第二层追问:为什么不是每个流程自己连 Postgres、OpenSearch、图数据库和 Redis?
platform 不只是存储。它把运行基础设施收口:run persistence、Redis buffer、QueryExecutorRouter、搜索/图查询适配、配置、观测、读模型守卫。业务价值是让一次 Web3 问数或报告数据包生成可执行、可持久、可恢复、可诊断。比如项目详情聚合、融资筛选、评分快照、新闻证据、关系图谱查询都要通过统一执行和观测能力;run、message、audit、RAG replay 也需要稳定持久化。没有 platform,Agent Bot 会被各种查询和证据细节污染。
理解与记忆 · 背后工程点
背后工程点:平台层让 Agent Bot 的查询、证据和回放稳定落地。
专业术语:
QueryExecutorRouter 是查询执行路由;
Search Adapter 是搜索索引适配;
Persistence 是运行和消息持久化;
Observability 是健康检查、trace 和依赖状态。
为什么这样回答:把“技术底座”翻译成业务可用性,避免模块堆砌。
小白解析:前台能问问题,后面还要有账本、搜索、图谱、缓存和监控,否则答错了也不知道错在哪。
关联知识点:主项目推荐架构包含主库、搜索、图谱、时序、缓存和对象存储;text2sql platform 承担 persistence、query executors、redis、config、observability。
面试官:下游报告 Agent 和系统 Agent 的依赖方向怎么设计?第二层追问:为什么报告 Agent 只消费 data pack,而不是自己调用 API、拼 SQL、抓新闻?
短期看更灵活,长期会失控。每个报告 Agent 自己查库,会重复实现实体消歧、指标口径、权限、来源引用、RAG 评测和错误回放;更严重的是,同一个“融资强”或“未 TGE”可能被不同报告 Agent 算成不同口径。系统 Agent 统一提供 data pack、evidence、artifact 和 runId,下游报告 Agent 只负责报告结构和叙事。这样数据事实集中治理,报告生成可以多样化。
系统 Agent 与报告 Agent 边界:主讲系统 Agent 为什么统一出 data pack,其他题只补权限、性能或踩坑角度。
理解与记忆 · 背后工程点
背后工程点:报告 Agent 应该消费受治理的数据包,而不是绕开系统直接查事实源。
专业术语:
Data Pack 是系统 Agent 输出的结构化数据包;
Evidence Contract 是来源和证据交付合同;
Single Source of Truth 是统一事实源;
Report Orchestration 是报告结构和叙事编排。
为什么这样回答:把下游 Agent 作为系统调用方纳入架构,能体现平台级设计。
小白解析:每个写报告的人都自己查账,很容易口径不一;统一让财务系统出数据,报告人负责写清楚。
关联知识点:主项目文档明确开发者 / AI Agent 是用户画像之一,API、Webhook、批量导出和变更流是商业化能力。
面试官:Intent Router 在架构里怎么设计?第二层追问:同一句话里既有问数又有咨询,怎么决定走 SQL、RAG、图查询、澄清还是报告数据包流程?
我会先做意图路由。纯事实问题,比如“本周融资额最高的项目”,走查询;解释类问题,比如“为什么这个赛道变热”,要先查数据和新闻证据,再生成投研解释;报告类问题,比如“生成周报”,要拆成多个数据子任务,返回 data pack 和图表规格,再组织叙事。关键是咨询也不能凭模型常识讲,必须基于主项目数据、来源文档和当前时间窗口。
理解与记忆 · 背后工程点
背后工程点:Agent Bot 要区分问数、解释、报告和澄清,但所有结论都要回到证据。
专业术语:
Intent Routing 是意图路由;
Analytical Answer 是基于数据证据的分析性回答;
Report Task Decomposition 是报告任务拆分;
Grounded Consulting 是基于证据的咨询。
为什么这样回答:老板要的不是 SQL,而是结论,但你要强调结论不能脱离数据。
小白解析:老板问“怎么看这个赛道”,助手可以分析,但先要拿事实,不是凭感觉讲故事。
关联知识点:主项目核心任务包括发现 Alpha、验证基本面、跟踪趋势和理解关系网络;Agent Bot 把这些任务自然语言化。
面试官:Semantic Modeling Layer 应该放在架构的哪个位置?第二层追问:在 Web3 主项目里,它到底建模表结构,还是建模投研口径?
它建模的是稳定投研语义,不只是数据库表。比如“融资强”可能绑定金额、轮次、投资人质量和时间窗口;“解锁压力”绑定未来解锁金额、供应占比和流通市值;“顶级投资人”绑定机构类型、历史 portfolio、lead 次数和活跃度;“未 TGE”绑定 token_status 和 TGE 日期。RAG 负责把相关证据找回来,Modeling Layer 把这些稳定定义变成可执行语义对象,semantic-plan 再决定怎么用。
理解与记忆 · 背后工程点
背后工程点:MDL 固化 Web3 投研口径,RAG 负责召回,semantic-plan 负责使用。
专业术语:
Metric 是业务指标;
Calculated Field 是计算字段;
Dimension 是分组和过滤维度;
Relationship Path 是声明式关联路径。
为什么这样回答:用未 TGE、解锁压力、顶级投资人这些具体口径回答,能和主项目贴合。
小白解析:系统要先知道“好项目”的判断规则,不能每次让模型临场猜。
关联知识点:Modeling Layer 文档列出 Models、Calculated Fields、Relationships、Metrics、Dimensions;主项目有评分、融资、Token、解锁和关系图谱。
面试官:RAG 层在架构里到底检索什么资产?第二层追问:为什么要把 lexical、dense、graph 做成三路召回,而不是一个向量库搞定?
它不只是搜索 schema,而是搜索 Web3 资产证据:表结构、术语、source_documents、news_articles、项目介绍、融资公告、历史查询样例、关系图谱和语义指标。lexical 适合命中项目名、Token 符号、机构名;dense 适合“AI x Crypto”“解锁压力”这类自然语言语义;graph 适合项目-机构-人物-生态的关系路径。三路召回融合后,系统才更容易同时找到事实、语义和关系。
理解与记忆 · 背后工程点
背后工程点:Text2SQL 的召回要同时覆盖词面、语义和关系。
专业术语:
Lexical Retrieval 是关键词和词面匹配;
Dense Retrieval 是向量语义检索;
Graph Retrieval 是基于关系图的召回;
RRF 是 Reciprocal Rank Fusion,融合多路排序。
为什么这样回答:把三路召回和 Text2SQL 的 schema linking 直接绑定。
小白解析:找人可以按身份证号、按长相相似、按朋友关系找,三种路一起更稳。
关联知识点:README 和 architecture 文档描述 lexical、dense、graph 三路召回、RRF 融合、rerank 和 selected_context;learn-RAG 索引优化强调给知识准备多条能被找到的路。
面试官:权限过滤应该放在检索、融合、重排、执行的哪个阶段?第二层追问:如果先重排再过滤,架构上会引入什么隐性数据泄漏?
先重排再过滤可能让无权表影响排序和上下文选择,即使最后删掉,它也可能间接影响模型判断,比如让模型倾向某条 join 路径或指标定义。更安全的做法是让检索和上下文装配都在可见范围内运行,至少在进入 selected context 前完成权限过滤,并把过滤状态写入 evidence。这样模型看到的是授权后的世界,而不是先看到再忘掉。
权限校验位置与 fail-closed:权限章主讲治理边界,流程、安全和踩坑章复用同一原则。
理解与记忆 · 背后工程点
背后工程点:权限不只是执行 gate,也是上下文 gate。
专业术语:
Permission Filtering 是权限过滤;
Context Contamination 是无权或错误信息污染上下文;
Selected Context 是最终给下游使用的证据包;
Risk Tags 是运行证据中的风险标签。
为什么这样回答:面试官会看你是否理解数据泄漏不一定发生在 SQL 执行时。
小白解析:不能先让你看机密文件,再说“请你忘掉”。
关联知识点:README 明确权限过滤先于融合和重排;业务逻辑文档提到 retrievalBundle 包含 selected_context、degrade_reasons、risk_tags。
面试官:Delivery Contract 为什么是一个独立架构边界?第二层追问:为什么要把 answer、evidence、artifact、data pack、runId 分开,而不是直接返回答案和 SQL?
不够。answer 是业务用户看的自然语言结论;evidence 是系统为什么这样回答,包括检索状态、降级原因、语义版本锁、risk tags、上下文摘要;artifact 是可复查的 SQL、列、行数、预览数据等工件。三者分开后,前端可以给普通用户展示简洁答案,也可以给分析师或开发者展示证据和调试信息。更重要的是 sync、stream、run view 和 replay 都能围绕同一份交付合同对齐。
证据链、data pack 与报告可追溯:可信结果章主讲 evidence/data pack 合同,其他章只补充报告 Agent 消费与复用场景。
理解与记忆 · 背后工程点
背后工程点:交付合同把用户体验和诊断证据统一起来。
专业术语:
Answer 是自然语言答案和状态;
Evidence 是证据、降级、风险和上下文摘要;
Artifact 是 SQL、结果列、行数、预览数据;
Delivery Contract 是前后端共享交付结构。
为什么这样回答:从用户、分析师和系统调试三种视角解释合同价值。
小白解析:结论、参考资料、计算草稿要分开装订,否则既不好读也不好查错。
关联知识点:business-logic 的 Delivery Contract 包含 answer、evidence、artifact;README 强调共享类型和 SSE 协议保持同步、流式、运行详情一致。
面试官:runId / trace / replay 在架构里怎么贯穿全链路?第二层追问:没有 runId,为什么不只是难排查,而是会破坏报告 Agent 的可信交付?
runId 是一次问数的事实锚点,不只是日志 id。Text2SQL 的结果来自检索、重排、语义计划、SQL 生成、校验、纠错、执行和交付多个阶段。没有 runId,就很难把同步响应、流式 finish、run view、RAG replay、audit log、delivery evidence 对齐。用户质疑答案时,我们需要按 runId 回看当时命中的证据、权限状态、SQL、执行结果和降级原因,而不是事后凭印象猜。
runId、trace、replay 与回放:可信结果章主讲 runId 可回放,架构、流程、时效和可观测章只从各自链路补充。
理解与记忆 · 背后工程点
背后工程点:runId 是跨阶段证据一致性的主键。
专业术语:
Trace Correlation 是跨日志和阶段关联;
Rag Replay 是检索和重排回放;
Audit Log 是审计事件;
Run Persistence 是运行持久化。
为什么这样回答:把 runId 从技术 id 提升成业务可信的证据锚点。
小白解析:像快递单号,没有它你很难知道包裹在哪个环节出问题。
关联知识点:README 提到每次运行都有 runId,可追溯 trace、RAG evidence、delivery artifact 和回放结果;database-schema 有 sql_runs、agent_audit_logs、rag_run_replays。
面试官:架构上如何设计 fail-closed、clarification 和 metadata answer 的边界?第二层追问:怎样既不乱执行,又不把用户体验做成到处拒绝?
会影响体验,但这是数据系统必须接受的权衡。我的策略不是所有不确定都直接拒绝,而是分层处理:能澄清的走 clarification,能直接回答元数据的走 metadata answer,能生成但权限或安全不确定的才 fail-closed。比如 SQL 解析不完整、出现写操作、多语句、未授权表,这些不能为了体验放行。更好的产品体验是说明拒绝原因,并提示用户补充信息或联系管理员,而不是静默冒险执行。
澄清策略、smart defaults 与回滚:澄清章主讲默认和必须追问的边界,评测和可观测章只补验证与监控。
- 16-ambiguity-clarification · q03
- 10-complex-analysis-planning · q06
- 11-semantic-layer-metric-governance · q19
- 13-observability-troubleshooting · q14
- 16-ambiguity-clarification · q01
- 16-ambiguity-clarification · q02
- 16-ambiguity-clarification · q11
- 16-ambiguity-clarification · q14
- 16-ambiguity-clarification · q19
理解与记忆 · 背后工程点
背后工程点:fail-closed 要和澄清、直接回答、错误解释配合。
专业术语:
Clarification 是澄清问题;
Metadata Answer 是不执行 SQL 的元数据回答;
Terminal Failure 是不可修复终止;
Read-only Guard 是只读 SQL 守卫。
为什么这样回答:不要把安全和体验对立,要讲可解释拒绝。
小白解析:银行转账信息不全时不能随便转,但应该告诉你缺了什么。
关联知识点:intake 会分流 general、clarification、unsafe、unsupported;safety-check 做 SELECT/WITH、禁写关键字、多语句拦截和授权校验。
面试官:架构演进后节点命名不一致怎么办?第二层追问:文档里有 `clarify/retrieve-knowledge/build-intent-plan`,也有 v2 的 `intake/retrieve/assemble-context/semantic-plan`,你面试时以哪条运行时主链为准?
我会主动说明这是架构演进造成的命名差异。早期业务逻辑文档里有 clarify、retrieve-knowledge、build-intent-plan、build-semantic-query、build-physical-plan 这套说法;当前我讲主链路时会以 Text2SQL v2 runtime 为准,也就是 `Text2SQLWorkflowRunner -> RunV2LangGraphStage -> Text2SqlV2LangGraphRunnerService`,节点叙事用 intake、retrieve、assemble-context、semantic-plan、generate-sql、validate、correct、execute、answer。这样能避免面试官觉得我把旧方案和当前实现混着讲。
运行时主链路与节点命名:流程章主讲当前 runtime 链路,架构和踩坑章只解释历史命名差异。
理解与记忆 · 背后工程点
背后工程点:架构文档会演进,面试时要能区分历史方案和当前主缝。
专业术语:
Runtime Seam 是当前请求进入运行时的主路径;
Legacy Node Naming 是早期文档里的节点命名;
Current Narrative 是当前实现的讲述口径;
LangGraph Stage 是图运行时阶段。
为什么这样回答:主动解释差异,比被追问后补救更像真正读过仓库。
小白解析:一家公司改过组织架构,旧文档和新文档叫法不同,汇报时要说清现在按哪个组织跑。
关联知识点:architecture-and-flow 文档明确当前主缝固定为 Text2SQLWorkflowRunner -> RunV2LangGraphStage -> Text2SqlV2LangGraphRunnerService。
面试官:架构上怎么证明 Knowledge/RAG 层真的能支撑 Text2SQL?第二层追问:gold evidence、Recall@K、MRR、NDCG 应该如何服务 schema linking 和 query planning?
我不会只看最终 SQL 是否执行成功,因为那会把检索、排序和生成混在一起。我会先做检索评测集:每个问题标注 gold evidence,比如必须命中的表、列、术语、指标、关系路径和历史样例。然后分别看 Hit Rate、Recall@K、MRR、NDCG:Recall@K 看关键证据有没有进候选,MRR 看第一个正确证据排得够不够靠前,NDCG 看多个证据的排序质量。最后再和 SQL 执行正确率、校验失败类型关联起来,判断是召回问题、重排问题还是生成问题。
RAG 召回质量与 gold evidence 评测:RAG 章主讲召回评测,评测章和优化章用于证明优化不是感觉更准。
理解与记忆 · 背后工程点
背后工程点:RAG 质量要分层评测,不能只看最终答案。
专业术语:
Gold Evidence 是人工标注的必需证据;
Recall@K 是前 K 个候选里召回正确证据的比例;
MRR 是第一个正确结果排名的倒数均值;
NDCG 是考虑多证据相关性和排序位置的指标。
为什么这样回答:面试官问“如何确保能搜到”时,必须给评测闭环,而不是说调 topK。
小白解析:不能只看最后考试及格,要拆开看资料有没有找对、重点有没有排前面、最后有没有写对答案。
关联知识点:learn-RAG 的召回质量检验强调 gold evidence、召回率和排序指标;text2sql 有 RagReplayRepository、RagQualityService 和质量门禁报告。
面试官:SQL validate / correct / execute 为什么是主架构链路,而不是执行前的安全小模块?第二层追问:它和权限、方言、dry-run、报告 Agent 交付有什么关系?
SQL 校验直接决定 Agent Bot 能不能安全拿到主项目数据,所以它是业务架构的主链路,而不是旁路安全模块。更准确地说,系统先校验 plan,再校验 SQL:SemanticPlan 和 PhysicalSqlPlan 要证明表、列、指标、join path、limit、dialect 都来自授权上下文;模型生成的 SqlGenerationOutput 还要过 AST、single statement、readonly、字段/表权限、dry-run、扫描成本和 semanticPlanMatched。列名、方言、GROUP BY 这类错误可以有界纠错;READONLY、ACL、未解析表字段、危险函数必须 terminal。它保障的是数据平台底线:查询可以失败,但不能越权、不能改数据、不能把未授权字段交给报告 Agent。
SQL 校验、执行安全与 correct loop:架构章主讲 validate/correct/execute 是主链路,安全章主讲攻击面和终止条件。
理解与记忆 · 背后工程点
背后工程点:执行安全是问数产品的核心业务能力。
专业术语:
SQL Validation 是 SQL 校验;
Dry-run 是试运行或预检查;
Correctable 是可修复错误;
Terminal 是必须终止的错误。
为什么这样回答:把安全从“后置检查”提升为“主链路阶段”。
小白解析:数据查询不是写作文,写错最多改字;SQL 写错可能查错数据或越权。
关联知识点:Text2SQL 主流程有 validate -> correct -> generate-sql 有界闭环;business-logic safety-check 和 execute-sql 都包含安全与授权检查。
面试官:Semantic Version Lock 在架构里解决什么问题?第二层追问:为什么 Web3 投研指标、榜单、融资强度和热度口径必须版本化?
Web3 投研口径会变,比如“热度指数”的权重、透明度分公式、融资强度定义、顶级投资人名单都会调整。如果运行时不锁定语义版本,同一个问题在不同时间可能用不同定义,报告也无法复查。语义版本锁就是在一次运行里明确使用哪个 domain、哪个 semanticVersion;如果指定版本不存在,可以 fallback 到 active 版本,失败则 degraded 并记录风险。这样 runId 回放时能知道当时的语义口径。
Semantic version 与指标口径回放:语义层主讲口径版本锁,架构和时效章补充 runId 回放与历史报告。
理解与记忆 · 背后工程点
背后工程点:版本化语义保证指标口径可复现。
专业术语:
Semantic Version 是语义版本;
Version Lock 是版本锁定;
Fallback 是回退到当前 active 版本;
Degraded 是降级状态。
为什么这样回答:用业务口径变更举例,面试官容易理解价值。
小白解析:同一道菜换了配方,必须知道当时用的是哪版配方。
关联知识点:business-logic 描述 SemanticRegistryService 管理 domain + semanticVersion,PlannerVersionLockService 优先锁定请求版本,不存在则 fallback 或 degraded。
面试官:架构上如何处理 RAG lane 超时、召回为空、来源置信度低这些降级场景?第二层追问:什么时候允许继续生成 SQL,什么时候必须澄清或 fail-closed?
这个项目的原则是 RAG 可降级但不静默。RAG lane 失败不会一定中止主路径,但 degradeReasons 和 riskTags 要进入 evidence。是否继续生成 SQL,要看问题风险和上下文是否足够:简单、低风险、schema 明确的问题可以弱检索继续;关键证据缺失、权限不明确或语义计划不满足时应该澄清或 fail-closed。重点是降级原因要可见,不能让用户以为这是完整证据下的高置信回答。
RAG 召回为空、低置信与降级:RAG 章主讲搜不到时如何表现,架构和澄清章补充继续、澄清、fail-closed 的边界。
理解与记忆 · 背后工程点
背后工程点:降级不是隐藏失败,而是带证据继续或终止。
专业术语:
Degrade Reasons 是降级原因;
Risk Tags 是风险标签;
Lane Timeout 是单路召回超时;
Weak Retrieval 是弱检索状态。
为什么这样回答:面试官会攻击“RAG 失败还敢跑”,你要讲分级策略。
小白解析:导航信号弱时可以走熟悉短路,但不能假装信号满格。
关联知识点:README 强调 RAG lane 可独立超时和降级,降级原因进入 evidence;business-logic 说明重排支持超时与预算降级,RAG 失败不会直接中止主查询路径。
面试官:从架构升级角度讲,你踩过哪些坑?第二层追问:从早期 prompt + SQL demo 升级到系统 Agent,哪些设计必须重做?
我会讲三个坑。第一,早期容易把 SQL 当事实源,觉得能跑就算对,后来发现 SQL 只是编译产物,真正事实源应该是 schema catalog、metric definition、policy、source documents 和 execution trace。第二,容易把 RAG 当 prompt 附件,检索结果直接拼进去,导致噪声大、权限和语义口径不可控,后来升级成 ACL-filtered selected context 和 semantic-plan。第三,容易把安全与回放放到最后,后来发现 prompt 前权限裁剪、plan validation、SQL validation、grounded answer 和 Text2SqlReplay 都必须进入主链路,否则错误没法定位,也没法转成 eval case。
理解与记忆 · 背后工程点
背后工程点:架构升级从 prompt demo 走向证据、治理和可回放。
专业术语:
Prompt Attachment 是把 RAG 当提示词附件;
Context Assembly 是上下文装配;
Validation Gate 是校验闸门;
Delivery Enrichment 是交付增强。
为什么这样回答:坑要讲架构演进,不要只怪模型。
小白解析:一开始像临时手工作坊,后来变成有质检、有记录、有流程的生产线。
关联知识点:architecture 文档总结 v1.3 从裸 LLM 升级为有证据的 RAG Text2SQL,v2.0 从内容检索升级为语义驱动生成,当前实现把运行证据和 delivery contract 工程化。
PRINCIPLE本章背诵原则
- 先讲总范式:Text2SQL 是 Query OS,不是 LLM 直接写 SQL。
- 再讲事实源:schema catalog、metric definition、policy、source documents、execution trace 才是事实源,prompt 只是编译结果。
- 运行时要讲对象:QuerySlots、SelectedContextPack、IntentPlan、SemanticPlan、PhysicalSqlPlan、SqlGenerationOutput、ValidationReport、GroundedAnswer、Replay。
- 权限要讲前置:未授权表列不能进入 selected context,也不能在 execute 前侥幸拦截。
- 校验要讲双层:plan 先验证,SQL 再验证;安全拒绝和可修复错误必须分开。
- 交付要讲忠实:answer 只能基于 question、SQL、columns、rows、assumptions 和 evidence,不允许编故事。
- 坑要讲飞轮:从 prompt 拼接和裸 SQL,升级到 selected context、plans、validation、grounded delivery 和 replay/eval。