OPENING30 秒开口版
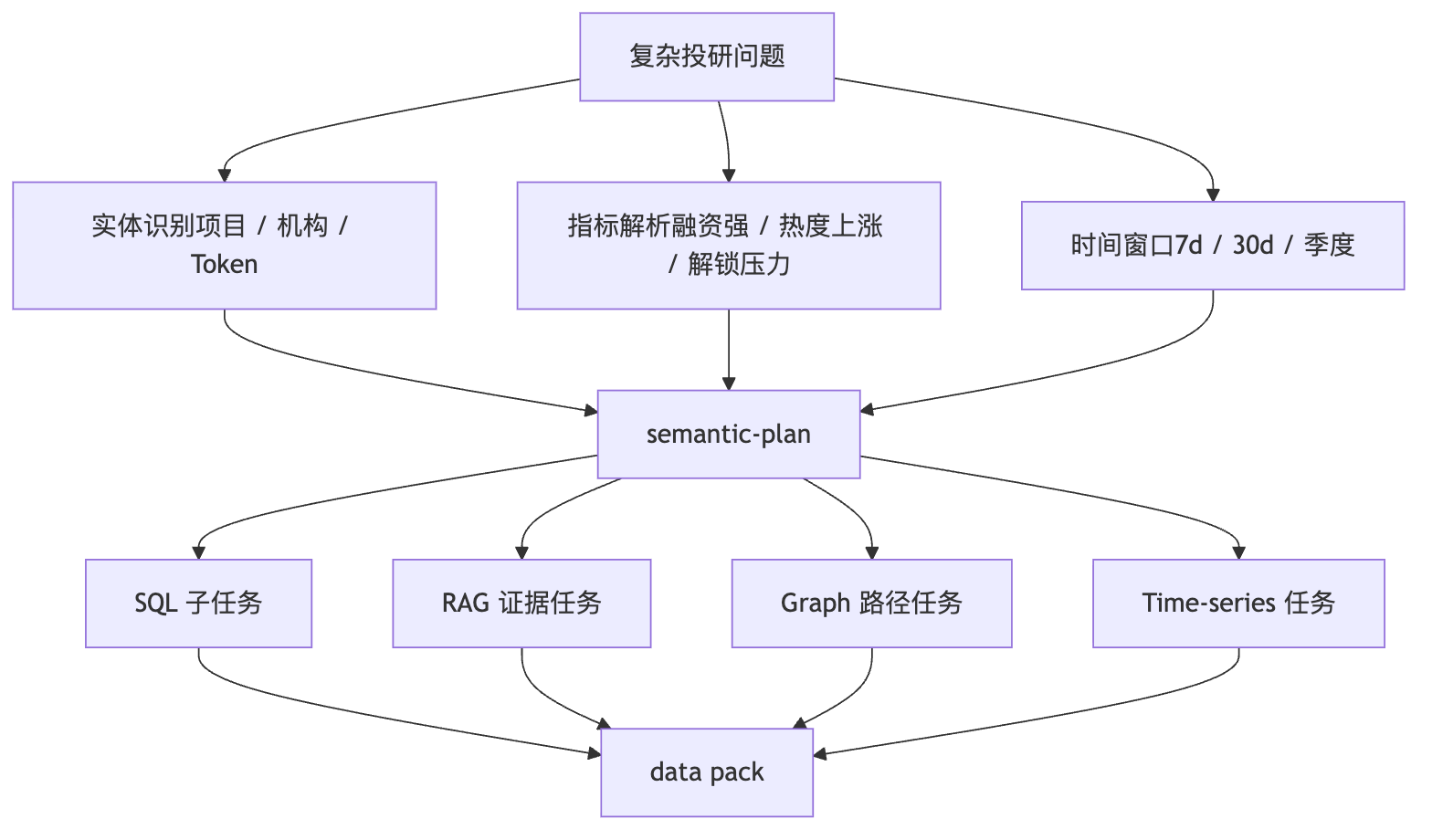
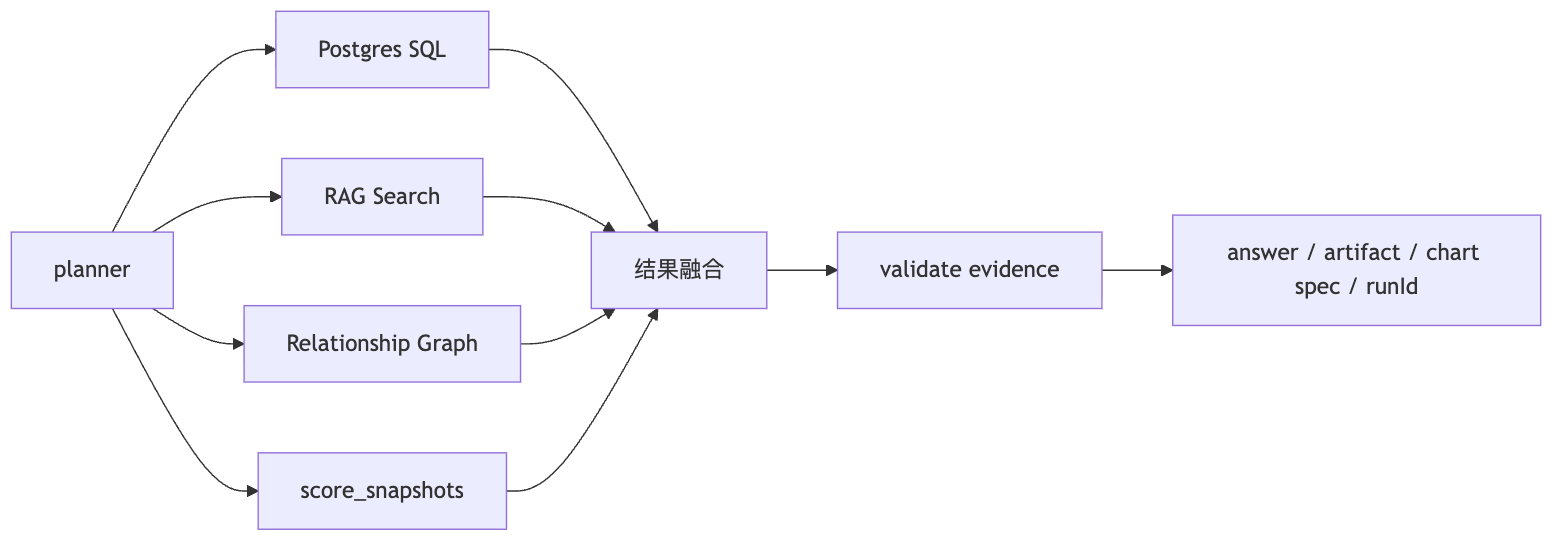
复杂分析问题我不会直接丢给 SQL 生成,而是先做 semantic-plan:识别实体、指标、时间窗口、业务口径、关系路径和输出形态,再决定哪些部分走 SQL、哪些走 RAG、哪些走 GraphRAG、哪些走时间序列。比如“找近期融资强、未 TGE、热度上涨的 AI Crypto 项目”,SQL 查项目和融资候选,RAG 补公告和赛道证据,图谱补机构和共同投资关系,时间序列查 score_snapshots,最后合成 data pack、evidence、chart spec 和 runId。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。 Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。 GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。 Data Pack:给老板或报告 Agent 的结构化结果、图表规格和证据集合。 |
| 为什么这样回答 | 复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。 |
| 小白解析 | 用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。 |
| 关联知识点 | text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。 |
1 MIN一分钟口语版
这类问题的难点不是 SQL 写得长,而是每个词都带业务语义。“近期”要确定时间窗口,“融资强”要确定金额、轮次和投资人质量,“未 TGE”要绑定 token_status 和 TGE 日期,“热度上涨”要绑定 score_snapshots,“AI Crypto”既可能来自标签也可能来自项目介绍和新闻。系统先通过 RAG 和语义层构造 selected context,再由 semantic-plan 输出子任务、join path、filters、排序规则、所需证据和执行路由。执行时可以是多 SQL、SQL + RAG、SQL + Graph、SQL + time-series,失败时返回部分结果或澄清,而不是让模型自由发挥。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。 Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。 GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。 Data Pack:给老板或报告 Agent 的结构化结果、图表规格和证据集合。 |
| 为什么这样回答 | 复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。 |
| 小白解析 | 用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。 |
| 关联知识点 | text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。 |
ARCHITECTURE架构设计要点
问题拆解
把一句投研问题拆成实体、指标、时间窗口、排序和输出要求。
执行路由
SQL 查结构化事实,RAG 查来源证据,Graph 查关系,时序查趋势。
中间产物
子任务结果、SQL artifact、路径证据、selected context 都绑定 runId。
失败控制
实体不稳、路径低置信、证据缺失时澄清、补检索或降级。
报告复用
输出 data pack、chart spec、source refs,报告 Agent 只组织叙事。
性能边界
限制图谱跳数、候选集大小、查询预算和并发任务。
DIAGRAM架构图
复杂问题如何被拆成计划
多引擎执行和交付
TABLE关键对象和面试讲法
| 对象 | 职责 | 面试强调 |
|---|---|---|
| AI x Crypto | 标签、项目介绍、新闻语义 | 可能需要 RAG 和实体标签共同判断。 |
| 未 TGE | tokens.token_status、tge_date | Token 状态冲突时要标记风险。 |
| 融资强 | funding_rounds、participants、investor tier | 金额、轮次、投资人质量组合。 |
| 热度上涨 | score_snapshots、访问、关注、社媒 | 必须绑定时间窗口。 |
| 共同投资 | funding_participants 图路径 | 适合 GraphRAG 或关系查询。 |
| 解锁压力 | token_unlock_events、供应占比 | 未来窗口和市场数据共同判断。 |
| 报告输出 | data pack、chart spec、source refs | 服务下游报告 Agent。 |
INTERVIEW MAP面试表达地图
- 先拒绝裸 SQL复杂分析不是一条 SQL 能稳定解决。
- 再拆语义实体、指标、时间、关系、排序。
- 讲多引擎SQL、RAG、Graph、Time-series 协同。
- 讲中间证据每一步都绑定 runId 和 artifact。
- 讲降级低置信时澄清、补检索、部分结果或 fail-closed。
SUBAGENTS面试官、候选人和红队
本章写作前已实际启动多 subagent:面试官 subagent 负责连续追问生产压力,候选人 subagent 负责把答案压成现场能讲出口的表达,资料审阅 + 红队 subagent 负责指出哪些地方容易写虚,并补充安全、评测、runId、下游报告 Agent 的攻击面。
本章追问重点:所有回答都要落到 RootData 类 Web3 主项目、Agent Bot、Text2SQL、RAG、runId/evidence/artifact/data pack 和下游报告 Agent 复用。
Q&A20 组高强度追问
面试官:“近期融资强、未 TGE、热度上涨的 AI Crypto 项目”怎么拆?
我:我会拆成四个过滤和一个排序:AI Crypto 是标签或文本语义,未 TGE 是 token_status 和 tge_date,融资强是融资金额、轮次和投资人质量,热度上涨是 score_snapshots 时间序列,最后按综合分排序并引用融资公告。
理解与记忆 · 背后工程点
背后工程点:复杂问题要拆成可执行语义组件。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:哪些走 SQL,哪些走 RAG,哪些走图谱?
我:项目、Token 状态、融资金额、热度快照走 SQL;公告来源、项目介绍、赛道证据走 RAG;机构共投、投资网络、生态关系走图谱;趋势变化走时间序列。
Query Planner 路由与避免全工具执行:流程章主讲路由判断,优化章主讲降本,复杂分析章主讲计划拆分。
理解与记忆 · 背后工程点
背后工程点:执行引擎要按数据形态选择。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:多步计划中间结果如何保存?
我:每个子任务生成 artifactRef,比如候选项目表、融资统计 SQL、证据列表、图路径摘要。它们都挂在同一个 runId 下,最终 data pack 引用这些 artifact。
理解与记忆 · 背后工程点
背后工程点:复杂分析要有中间产物,方便复查和复用。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:如果第一步实体召回不稳定,会污染后续 SQL 吗?
我:会,所以实体识别要有置信度和消歧。低置信实体不直接进入 SQL filter,而是触发澄清、候选列表确认或补检索。
理解与记忆 · 背后工程点
背后工程点:实体消歧是复杂计划的前置安全阀。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:共同投资网络为什么不能只靠向量检索?
我:因为它问的是关系路径,不是相似文本。需要 funding_participants 里的机构和轮次关系,GraphRAG 可以扩展路径,但最终仍要回到融资事件和来源证据。
GraphRAG、图查询与图数据库:复杂分析章主讲共同投资网络为什么走图,评测、排障和性能章分别补充质量、错误定位和成本。
理解与记忆 · 背后工程点
背后工程点:关系问题需要图路径和事实证据。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:复杂问题什么时候澄清?
我:当歧义会显著改变结果时澄清,比如“近期”要 7 天还是 90 天,“融资强”按金额还是投资人质量,“Apple”是哪个实体。低风险默认可以执行并说明默认值。
澄清策略、smart defaults 与回滚:澄清章主讲默认和必须追问的边界,评测和可观测章只补验证与监控。
- 16-ambiguity-clarification · q03
- 01-business-architecture · q14
- 11-semantic-layer-metric-governance · q19
- 13-observability-troubleshooting · q14
- 16-ambiguity-clarification · q01
- 16-ambiguity-clarification · q02
- 16-ambiguity-clarification · q11
- 16-ambiguity-clarification · q14
- 16-ambiguity-clarification · q19
理解与记忆 · 背后工程点
背后工程点:澄清要看歧义对结果影响。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:如何控制模型不要自由发挥分析计划?
我:planner 输出结构化 schema:metrics、dimensions、filters、joinPaths、evidenceRefs、route、budget。后续节点只消费这个结构,不接受自由文本计划直接执行。
理解与记忆 · 背后工程点
背后工程点:计划要结构化,不是模型散文。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:报告 Agent 要融资周报 data pack,你返回什么?
我:返回本周融资总额、笔数、赛道分布、Top 项目、Top 投资人、代表融资事件、图表规格、来源列表、SQL artifact、riskTags 和 runId。
系统 Agent 与报告 Agent 边界:主讲系统 Agent 为什么统一出 data pack,其他题只补权限、性能或踩坑角度。
理解与记忆 · 背后工程点
背后工程点:报告 Agent 需要结构化数据包,不只是摘要。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:多跳关系查询如何避免性能爆炸?
我:限制跳数、候选实体数量和边类型,常用共投关系做预聚合或缓存,graph lane 超时则降级为 SQL topN 关系,不让图查询拖垮主链。
缓存、物化视图与批量性能:性能章主讲缓存/物化/批量保护,优化章和复杂分析章只补充业务场景。
- 14-performance-cost-concurrency · q02
- 06-optimizations · q04
- 06-optimizations · q08
- 06-optimizations · q14
- 10-complex-analysis-planning · q18
- 12-freshness-source-consistency · q02
- 14-performance-cost-concurrency · q03
- 14-performance-cost-concurrency · q04
- 14-performance-cost-concurrency · q07
- 14-performance-cost-concurrency · q13
理解与记忆 · 背后工程点
背后工程点:图谱能力要有预算和降级。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:复杂分析失败时给部分结果还是 fail-closed?
我:取决于失败类型。证据不足或图谱超时可以返回部分结果并标记 degraded;权限不明、SQL 安全不通过、指标口径冲突严重则 fail-closed 或澄清。
理解与记忆 · 背后工程点
背后工程点:失败处理要按风险分层。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:如何把每一步计划绑定到同一个 runId?
我:workflow 入口生成 runId,所有子任务、SQL artifact、RAG replay、graph path、delivery evidence 都写入这个 runId 的 trace 或 artifactRefs。
runId、trace、replay 与回放:可信结果章主讲 runId 可回放,架构、流程、时效和可观测章只从各自链路补充。
理解与记忆 · 背后工程点
背后工程点:runId 是复杂分析的统一上下文。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:如果用户追问“为什么这些项目排前面”,系统怎么答?
我:复用上一次 runId 的 artifact,展示排序字段、权重口径、每个项目的融资和热度证据。追问不重新猜原因,而是解释已有 data pack。
理解与记忆 · 背后工程点
背后工程点:追问应基于已有产物,而不是重新生成幻觉。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:复杂分析里 SQL 可能很多,如何保证一致性?
我:同一次 run 锁定 semanticVersion、数据快照时间和权限版本。多条 SQL 使用同一时间窗口和同一实体候选集,避免前后口径漂移。
理解与记忆 · 背后工程点
背后工程点:多查询要共享版本和上下文。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:如何处理结构化结果和新闻热度不一致?
我:把它作为多源冲突展示。比如结构化评分没涨,但新闻数量增加,可以标记热度证据分歧,并解释当前排序主要依赖哪类信号。
理解与记忆 · 背后工程点
背后工程点:复杂分析要显式处理信号冲突。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:Query Planner 和 semantic-plan 有什么区别?
我:semantic-plan 更关注业务语义落地,Query Planner 更关注执行路由和预算。实际实现里可以合并,但面试表达上要说明先理解业务,再选择执行方式。
Query Planner 路由与避免全工具执行:流程章主讲路由判断,优化章主讲降本,复杂分析章主讲计划拆分。
理解与记忆 · 背后工程点
背后工程点:理解和执行是两个层次。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:复杂分析是否需要长期记忆?
我:高质量的历史问答、验证过的 SQL 和报告模板可以晋升为 memory 或 saved prior SQL,但必须带来源、版本和适用范围,不能把一次结果当永久事实。
理解与记忆 · 背后工程点
背后工程点:复用要有治理,不能污染未来。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:怎样让复杂分析可测试?
我:把复杂问题拆成子任务 gold:实体 gold、指标 gold、SQL result、图路径 gold、source evidence。每一段失败都能单独定位。
理解与记忆 · 背后工程点
背后工程点:复杂任务评测也要分解。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:什么时候用物化视图?
我:融资趋势、热门榜、Token 解锁日历这类高频聚合适合预计算。临时复杂筛选仍走实时 SQL,但可以复用预聚合基础表。
缓存、物化视图与批量性能:性能章主讲缓存/物化/批量保护,优化章和复杂分析章只补充业务场景。
- 14-performance-cost-concurrency · q02
- 06-optimizations · q04
- 06-optimizations · q08
- 06-optimizations · q14
- 10-complex-analysis-planning · q09
- 12-freshness-source-consistency · q02
- 14-performance-cost-concurrency · q03
- 14-performance-cost-concurrency · q04
- 14-performance-cost-concurrency · q07
- 14-performance-cost-concurrency · q13
理解与记忆 · 背后工程点
背后工程点:复杂分析性能要靠预计算和实时查询结合。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:如何避免复杂分析输出太长?
我:delivery 分层:先给结论和 TopN,展开可看证据、SQL、图路径和完整表。报告 Agent 接口拿完整 data pack,人类 UI 默认压缩。
理解与记忆 · 背后工程点
背后工程点:交付层要服务不同消费者。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
面试官:一句话总结复杂分析设计。
我:复杂分析不是让模型一次性想明白,而是用 semantic-plan 把投研问题拆成可执行、可校验、可回放的多引擎任务。
理解与记忆 · 背后工程点
背后工程点:总结要回到计划和可回放。
专业术语:Semantic Plan:把业务问题转成指标、实体、关系、时间和路由的结构化计划。
Query Planner:选择 SQL、RAG、图谱、时间序列等执行引擎的规划器。
GraphRAG:通过实体和关系路径增强复杂检索,不等于单纯接图数据库。
为什么这样回答:复杂问题要体现架构拆解能力。先讲 planner,再讲多引擎路由,比直接说 LLM 多步推理更像生产系统。
小白解析:用户一句话可能其实包含好几个小问题。系统要先把它拆成清单,再分别查表、找来源、看关系,最后合并成一份可解释结果。
关联知识点:text2sql 当前主链路里 semantic-plan 决定继续 SQL、直接回答、澄清或 fail-closed。learn-RAG 的 GraphRAG 资料强调复杂问题需要实体、关系、路径和原文证据共同参与。
PRINCIPLE本章背诵原则
- 复杂问题先规划,再执行。
- SQL、RAG、Graph、Time-series 各做擅长的事。
- 每个子任务都要有 artifact 和 evidence。
- 低置信实体和路径不能直接污染后续查询。
- 报告 Agent 复用 data pack,不复用自由文本。