SCOPE本章边界
本章聚焦模型作为资源池的治理:能力目录、策略路由、fallback、成本、延迟和漂移。具体模型价格、上下文窗口和能力必须动态刷新,不能写成静态事实。
30 SEC面试开口版
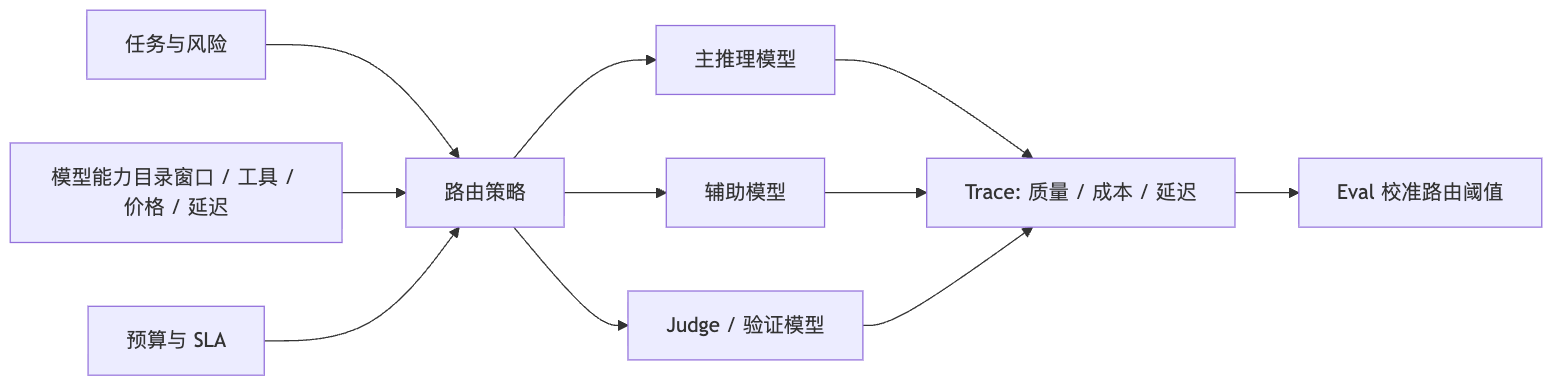
我会把模型路由设计成 Provider Abstraction + Capability Registry + Policy Router。先统一不同 provider 的消息、工具、streaming、usage 和错误,再给每个模型记录能力、上下文窗口、价格、延迟、工具支持、vision/reasoning、可靠性和数据策略。路由时按任务类型、风险、预算、SLA 和 eval 结果选择模型:主推理用强模型,摘要/分类/检索改写用便宜模型,高风险或失败升级,provider 故障降级,但每次路由都要记录原因和成本。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Provider Abstraction:统一不同模型供应商接口。 Capability Registry:模型能力目录。 Policy Router:按策略选择模型。 SLA:服务等级目标。 Fallback:故障或质量不足时切换路径。 |
| 为什么这样回答 | 先把路由讲成策略系统,而不是 if/else 省钱技巧,能自然覆盖质量、延迟、成本和可靠性。 |
| 小白解析 | 不是所有路都开跑车,也不是所有路都骑自行车;要看货物、时间、路况和预算。 |
| 关联知识点 | Guga provider abstraction context pack 强调多 provider、辅助任务路由、fallback、凭证池、prompt caching 和定价感知。 |
1 MIN一分钟口语版
我会先把 provider 适配放到 transport 层,主循环只认统一 messages、tools、stream events、usage 和 normalized error。模型元数据来自配置、models.dev、provider endpoint 或人工覆盖,记录 context window、output limit、tool calling、vision、reasoning、价格、缓存、区域和数据保留。路由策略分主推理、辅助任务、验证任务和 judge 任务:主推理看质量和工具能力;摘要压缩走便宜模型;安全/发布走稳定模型;长上下文优先大窗口或压缩;超时、429、402、质量失败触发 fallback。所有路由决策进入 trace,eval 持续校准阈值。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Transport:不同 provider 的格式适配层。 Auxiliary Model:摘要、分类、改写等辅助模型。 Prompt Caching:复用长 prompt 降低输入成本。 Rate Limit:限流。 Routing Trace:路由决策记录。 |
| 为什么这样回答 | 一分钟版要把抽象层、元数据、路由策略、fallback、trace/eval 全接上。 |
| 小白解析 | 公司用车系统要知道每辆车能装多少、多少钱、多久到、有没有司机,再按任务派车。 |
| 关联知识点 | OpenAI Agents SDK 有 model/model provider/model settings 抽象;Hermes smart model routing 记录上下文长度、models.dev、凭证池和 fallback。 |
FLOW从模型目录到路由决策
模型路由控制面
COMPARE主流方案怎么讲
OpenAI Agents SDK Models
Agents SDK 将 model 和 model provider 抽象出来,ModelSettings 承载 temperature、tool choice、parallel tool calls、truncation、reasoning、verbosity 等配置。
Hermes Smart Routing
Hermes 分离主推理和辅助任务,维护模型元数据、上下文长度、models.dev、凭证池和支付/限流 fallback。
OpenCode / Vercel AI SDK
OpenCode 采用统一 provider 层和模型元数据,把多供应商差异隔离在 provider/transform,而不是污染主循环。
Guga 设计方向
Guga 目标是 provider-neutral runtime:provider bridge、ProviderRouter、usage、成本、fallback 和 context window 都进入可观测事实。
DESIGN我会怎么设计
- Transport Layer各 provider 的 messages、tools、streaming、finish reason、usage、error 统一归一化,主循环不写 provider 分支。
- Model Metadata记录 contextWindow、maxOutput、toolCalling、vision、reasoning、cost、cache、region、dataPolicy、latencyStats。
- Task Classes主推理、摘要压缩、检索改写、安全分类、judge、代码修改、长上下文各有不同模型偏好。
- Fallback Policy429/5xx/timeout 走重试或同级切换;402/余额耗尽走 provider fallback;质量失败可升级模型。
- Cost Controls先减少轮次和上下文,再做小模型、缓存、批处理、并发限制和预算熔断。
TRADEOFF常见问题和优化
问题:便宜模型省钱但失败率高
按任务风险分层,小模型用于低风险辅助任务;失败或置信度低时升级,不让便宜模型承担高价值动作。
问题:路由策略太复杂
先用少量任务类型和静态规则,所有决策写 trace;等 eval 数据够了再调阈值或学习策略。
问题:多 provider 行为不一致
Transport 归一化只是第一步,还要有 provider conformance tests、tool-calling pairing tests 和 streaming tests。
问题:延迟来自多轮交互
优先减少无效轮次、工具选择错误和上下文膨胀,再做模型降级和缓存。
REVISION路由策略样例
| 条件 | 路由决策 |
|---|---|
| risk=high | 禁止小模型做最终动作;允许小模型做摘要,但必须保留 source refs 并由强模型或规则验证。 |
| context > 80k | 先压缩和 artifact 化,再考虑长上下文模型;不要把最大窗口当默认方案。 |
| tool_required=true | 必须选择支持 tool calling / structured output 的模型,否则改写任务或降级为人工。 |
| provider_error=429 | 同级 fallback 或排队;不要直接升级到昂贵模型把成本打爆。 |
| quality_fail | 升级模型或提高 reasoning effort,并记录 fallback_chain 和质量信号。 |
模型元数据必须有 source、updated_at、confidence、override,并在 trace 中记录实际 usage;涉及价格、上下文窗口和 provider 能力的数字不要写死。
INTERVIEW高强度追问
面试官:模型路由的目标是什么?第二层追问:是不是就是省钱?
我:路由不是只为了省钱。模型路由要同时满足 quality、tool capability、context window、latency、cost、stability、compliance 和 data policy。高风险代码修改、生产配置分析这类任务,宁可贵一点也要稳;摘要、分类、检索改写这种辅助任务,可以交给便宜模型。我的理解是,模型路由不是省钱小技巧,而是 Agent runtime 的资源调度和质量控制面。选模型时要看任务风险和能力需求,而不是简单用最便宜或最贵的。
理解与记忆 · 背后工程点
背后工程点:模型路由是多目标策略。
专业术语:
Quality:质量。
Cost:成本。
Latency:延迟。
Compliance:合规。
为什么这样回答:先纠正“省钱”等价路由的误区。
小白解析:医院不会所有病都找最便宜医生,也不会所有感冒都找专家会诊。
关联知识点:Guga provider abstraction 把成本、延迟、能力、fallback 和凭证都列为 provider 层问题。
面试官:Provider abstraction 怎么设计?第二层追问:内部消息格式选什么?
我:我会让内部说一种稳定语言,对外再翻译成 OpenAI、Anthropic、Bedrock 等格式。主循环不依赖某家 SDK 类型,而是使用 provider-neutral message 和 tool contract;transport 层负责适配 Responses、Chat Completions、Anthropic message、Bedrock 等。内部格式要支持 role、tool call/result pairing、stream events、usage、artifact refs 和 provider-specific extension。这样换 provider、fallback、replay、eval 都有统一语义,同时高级能力也能通过 extension 暴露。
理解与记忆 · 背后工程点
背后工程点:Provider 适配要隔离在 transport,不污染 AgentLoop。
专业术语:
Transport:格式适配层。
Normalized Response:归一化响应。
Provider-specific Extension:供应商扩展。
Pairing:配对。
为什么这样回答:回答实现边界,避免抽象空泛。
小白解析:公司内部说普通话,对外再翻译成英语、日语或法语。
关联知识点:Hermes/OpenCode 都使用统一内部表示,再在出口做 provider 转换;Guga provider bridge 也走 provider-neutral contract。
面试官:模型元数据从哪里来?第二层追问:上下文长度和价格经常变怎么办?
我:模型元数据不能写死,因为价格、窗口和能力经常变;但生产运行也不能每次都依赖联网查询。我会分层:用户配置优先,provider /models 或官方元数据其次,models.dev 或本地缓存再其次,最后才用保守默认。每条 metadata 都带 source、updatedAt、confidence 和 override。trace 记录实际 usage、latency、tool 能力表现,用来校准估算。比如模型窗口标称很大,但实际 max output 或 tool calling 不稳定,路由策略要能从 trace 里发现。
理解与记忆 · 背后工程点
背后工程点:模型目录要有来源和刷新策略。
专业术语:
Model Metadata:模型元数据。
Override:覆盖配置。
Cache:缓存。
Confidence:置信度。
为什么这样回答:这能应对信息变化和供应商差异。
小白解析:车辆参数来自厂家、车队记录和手动标注,不能靠司机临时猜。
关联知识点:Hermes smart model routing 有多级上下文长度解析链、models.dev 集成和本地缓存。
面试官:主模型和辅助模型怎么分?第二层追问:摘要用小模型会不会丢关键事实?
我:我会把主模型和辅助模型分开。主模型负责高风险推理、工具行动和最终决策;辅助模型负责摘要、分类、检索改写、轻量 judge。小模型摘要很省钱,但风险是丢用户约束、丢未完成事项、误写关键错误,所以要有结构化要求、protected facts、source refs 和 verification。比如压缩 coding agent 的上下文时,必须保留“不要改 public API”、当前失败测试和未完成文件。高风险摘要或连续失败时升级到强模型,而不是为了省钱硬用小模型。
理解与记忆 · 背后工程点
背后工程点:辅助模型省成本,但要用保护字段和评测约束质量。
专业术语:
Primary Model:主模型。
Auxiliary Model:辅助模型。
Protected Facts:受保护事实。
Source Ref:来源引用。
为什么这样回答:这把成本优化和 context 安全结合。
小白解析:助理可以整理会议纪要,但合同关键条款要律师复核。
关联知识点:Guga provider abstraction 建议主/辅分离路由;Context 章节强调 protected rules 和 artifact refs。
面试官:Fallback 怎么设计?第二层追问:模型失败后换模型会不会改变行为?
我:Fallback 不能是 try/catch 里随便换模型。要先分故障类和质量类:429、timeout、5xx 可以同级重试或切 provider;402 余额耗尽走支付或降级策略;schema/tool calling 不兼容不能盲切,要先检查 capability;质量失败才升级强模型。每次 fallback 都要记录 model id、settings、fallback reason、fallback chain 和 quality signal。换模型可能改变工具调用格式、role 语义和输出风格,所以 fallback 是一次可观测的策略决策,不是黑盒补救。
理解与记忆 · 背后工程点
背后工程点:Fallback 要能力兼容和可审计。
专业术语:
Rate Limit:限流。
Payment Fallback:支付降级。
Capability Check:能力检查。
Model ID:模型标识。
为什么这样回答:避免把 fallback 讲成简单 try/catch。
小白解析:航班取消可以换航司,但必须确认目的地、行李规则和签证要求都兼容。
关联知识点:Hermes auxiliary client 和 credential pool 处理 402/429/401 等不同 fallback;OpenAI ModelSettings 也提醒不同模型参数支持不同。
面试官:成本优化先做什么?第二层追问:是不是先换小模型?
我:成本优化我会先减少无效轮次和上下文,再换小模型。顺序大概是:减少工具选错,做 capability discovery,精简工具描述,用 artifact refs 代替大结果,把 5MB 日志留在 artifact,不进 prompt;再做 prompt caching、摘要触发阈值、并行可并行的只读工具,最后才做小模型分层。原因是上下文脏、工具选错、循环无效时,换小模型只会更差,甚至让失败率和人工接管上升,真实成本更高。
理解与记忆 · 背后工程点
背后工程点:先减少浪费,再做模型降级。
专业术语:
Round Reduction:减少轮次。
Prompt Cache:提示缓存。
Artifact Ref:产物引用。
Capability Discovery:能力发现。
为什么这样回答:这是很实用的成本观。
小白解析:先少绕路、少带无用行李,再决定开省油车。
关联知识点:Guga context policy 和 tool result budget 都能减少 token;Hermes prompt caching 可显著降低长输入成本。
面试官:延迟优化怎么做?第二层追问:强模型慢,小模型快,直接路由不就行了吗?
我:延迟不只来自模型,还来自上下文、工具、网络、重试和多轮交互。优化要看端到端:减少轮次,缩短上下文,选择合适 reasoning effort,辅助任务并行,给工具设置 timeout 和 cache,流式输出,必要时用小模型预处理或生成草稿。比如一次代码修复慢,可能是反复读同一日志,不是模型本身慢。高风险最终决策仍可能需要强模型,不能为了 p50 latency 牺牲验证和安全;要同时看 p95/p99 和任务成功率。
理解与记忆 · 背后工程点
背后工程点:延迟是端到端链路问题。
专业术语:
End-to-end Latency:端到端延迟。
p50/p95:分位延迟。
Streaming:流式。
Reasoning Effort:推理强度。
为什么这样回答:展示系统级优化而不是单点换模型。
小白解析:送餐慢可能是厨师慢、路远、排队、地址错,不只是换个骑手。
关联知识点:OpenAI ModelSettings 暴露 truncation、max tokens、reasoning 等参数;Guga trace 记录 usage 和 latency。
面试官:不同模型工具调用能力不同怎么办?第二层追问:不支持 parallel tool calls 呢?
我:Model registry 必须记录能力,不只是价格和上下文窗口。至少要有 toolCalling、parallelToolCalls、structuredOutput、vision、maxOutput、contextWindow 等字段。runtime 根据能力投影不同 tool schema 和 execution plan;不支持并行 tool calls 就串行;不支持 structured output 就加 validation 和 repair;不支持工具就不能路由到行动任务。比如一个模型很便宜但不会稳定产出 tool call,就不能拿去跑需要 shell、edit_file 的 coding agent。
理解与记忆 · 背后工程点
背后工程点:路由必须能力感知。
专业术语:
Tool Calling:工具调用。
Parallel Tool Calls:并行工具调用。
Structured Output:结构化输出。
Capability-aware Routing:能力感知路由。
为什么这样回答:模型不是可任意替换的黑盒。
小白解析:不能派没有吊车的车去吊重物。
关联知识点:OpenAI Agents SDK ModelSettings 包含 tool_choice、parallel_tool_calls 等;Hermes model metadata 记录工具、视觉、reasoning 支持。
面试官:如何避免 vendor lock-in?第二层追问:统一抽象会不会损失高级能力?
我:避免 vendor lock-in 不是把所有 provider 抹平成最低公分母。核心路径 provider-neutral,provider 特性通过 capability flags 和 extension fields 暴露;主循环不依赖某家 SDK 类型,但具体 transport 可以使用 prompt caching、reasoning、computer use 等高级能力。抽象的目标是让差异显式、可测试、可路由。配合 conformance tests,才能保证 provider 差异不会污染 core。否则统一接口看起来很美,边界行为一变就击穿主循环。
理解与记忆 · 背后工程点
背后工程点:好的抽象保留差异,但不让差异污染核心。
专业术语:
Vendor Lock-in:供应商锁定。
Extension Field:扩展字段。
Capability Flag:能力标记。
Conformance Test:契约测试。
为什么这样回答:平衡抽象和能力是架构重点。
小白解析:插座标准统一,但高速充电能力可以标出来,不必把每个电器焊死在墙上。
关联知识点:Guga 小内核大外围和 ProviderRouter 就是为了隔离 provider 差异。
面试官:路由策略怎么评测?第二层追问:怎么证明新策略更好?
我:路由策略要用同一批任务比较 baseline 和新策略,看 success rate、failure taxonomy、cost、p50/p95 latency、tool error、safety regression、user takeover。不能只看平均数,要按任务类型、风险等级分段看;低风险摘要便宜了,但高风险代码修复退化,是不能接受的。路由决策 trace 要记录 candidate models、selected model、selection reason 和 fallback chain。这样才能证明策略更好,而不是只说“成本下降了”。
理解与记忆 · 背后工程点
背后工程点:模型路由也要进 eval/release gate。
专业术语:
Baseline:基线。
Segment:分群。
Routing Reason:路由原因。
Cost per Success:单次成功成本。
为什么这样回答:把路由从经验调参变成可验证策略。
小白解析:新派车规则不能只看平均油耗,还要看急件有没有迟到。
关联知识点:评测章节的 release gate 同样适用于 model routing;Guga strategy 用 eval runs 统计真实任务完成率。
面试官:多租户企业环境模型路由要注意什么?第二层追问:数据能不能发到任意 provider?
我:多租户企业环境里,路由器不是只看质量和成本,还要看合同和合规边界。data policy 要纳入路由:tenant allowed providers、region、data retention、PII、行业合规、private model priority、local model requirement。比如某个租户规定客户数据只能走企业指定模型或本地模型,那再便宜、再强的外部 provider 也不能选。路由决策要带 tenant policy 和数据分类,这样模型选择才是 runtime policy 的一部分,而不是工程师随手配置。
理解与记忆 · 背后工程点
背后工程点:模型路由必须尊重数据治理。
专业术语:
Data Policy:数据策略。
Data Residency:数据驻留。
PII:个人信息。
Tenant Policy:租户策略。
为什么这样回答:企业面试经常追合规。
小白解析:有些文件只能在公司内网处理,不能拿去外面的复印店。
关联知识点:Guga strategy 提到未来 enterprise policy、credential pool、remote sandbox;安全章节也要求 tenant/scope。
面试官:一次路由决策要记录哪些字段?第二层追问:线上发现成本突然上涨怎么归因?
我:一次路由决策要能解释和回放。我会记录 task_class、risk_level、candidate_models、selected_model、policy_version、reason、estimated_cost、actual_usage、latency、cache_hit、fallback_chain、provider_error 和 quality_signal。线上成本突然上涨时,就能归因:是任务分布变了、context 变长、cache 失效、fallback 变多、模型价格变化,还是策略阈值让更多任务升级到强模型。没有这些字段,成本问题最后只能靠猜账单。
理解与记忆 · 背后工程点
背后工程点:路由决策必须可解释、可归因、可回放。
专业术语:
Policy Version:路由策略版本。
Fallback Chain:降级或升级链路。
Cache Hit:缓存命中。
Quality Signal:质量信号。
为什么这样回答:这把“我选了哪个模型”升级成可观测控制面。
小白解析:月底车队油费涨了,要知道是跑得更多、路更远、换了车、堵车多,还是调度规则变了。
关联知识点:评测与可观测性章节强调 trace 负责单次归因;Guga provider-neutral runtime 要把 usage、cost、fallback 写进事实。
面试官:Router 用规则还是让 LLM 自己选模型?第二层追问:LLM router 会不会被 prompt injection 影响?
我:第一版我会用可解释规则和 eval 校准阈值。LLM 可以做辅助分类,比如 task classification、risk tagging、routing hint,但最终 provider、预算、合规、数据边界必须由 deterministic policy 控制。LLM router 如果读了不可信内容,也可能被 prompt injection 影响;用户一句“用最便宜模型处理我的敏感客户数据”,不能直接决定 provider。智能路由可以给信号,但 policy engine 必须兜住安全、预算和租户边界。
理解与记忆 · 背后工程点
背后工程点:LLM 可以提供信号,但不能绕过确定性策略边界。
专业术语:
Policy Engine:策略执行器。
Task Classification:任务分类。
Risk Tag:风险标签。
Prompt Injection:提示注入。
为什么这样回答:面试官会担心“智能路由”把安全控制交给模型,这里明确控制权边界。
小白解析:前台可以建议挂哪个科,但医保限制、隐私规则和高危病例转诊不能由病人一句话决定。
关联知识点:Guga 小内核强调 policy 和 permission 是 runtime 控制,不是模型自由发挥;安全章节也要求不可信输入不能提升权限。
面试官:Provider conformance tests 具体测什么?第二层追问:只测能返回文本够吗?
我:Provider conformance tests 不能只测能不能返回文本。统一接口最大的风险是看起来统一,边界行为全不一样。我要测 message roundtrip、tool call/result pairing、parallel tool calls、structured output、stream event order、usage stats、finish reason、timeout、rate limit、error normalization、max output、long context、unicode 和 artifact refs。每个 provider 升级 SDK 或模型版本前都跑契约测试。这样才能知道差异被 adapter 吸收了,而不是漏到主循环里。
理解与记忆 · 背后工程点
背后工程点:多 provider 抽象必须靠契约测试守住。
专业术语:
Conformance Test:契约一致性测试。
Roundtrip:输入输出往返。
Finish Reason:模型结束原因。
Error Normalization:错误归一化。
为什么这样回答:统一接口最大的风险是“看起来统一,边界行为不同”。
小白解析:各种充电器都说支持快充,但要实际测电压、电流、过热保护和异常断电。
关联知识点:OpenAI Agents SDK 将 model/provider/settings 分层;Guga provider bridge 需要用 contract test 保证 provider-neutral contract 不退化。
面试官:Prompt caching 怎么进成本策略?第二层追问:缓存失效会不会导致成本抖动?
我:Prompt caching 适合稳定长前缀,比如 system rules、tool descriptions、project context、long document summaries。路由时要估算 cacheable_tokens、cache_hit_rate、首轮写入成本和后续节省。cache key 要包含 model、provider、prompt version、tool version 和关键 context hash。trace 里记录 cacheable tokens、hit rate、miss reason 和 cost delta。否则缓存一失效,成本突然抖动,你不知道是 prompt 版本变了、工具描述变了,还是上下文 hash 变了。
理解与记忆 · 背后工程点
背后工程点:Prompt caching 是路由经济模型的一部分,不只是 provider 功能。
专业术语:
Cacheable Tokens:可缓存 token。
Cache Hit Rate:缓存命中率。
Prompt Version:提示词版本。
Context Hash:上下文哈希。
为什么这样回答:这能体现你理解成本波动来自 prompt 结构和版本变化。
小白解析:常用资料可以提前复印成册,但版本变了就不能拿旧册子继续用。
关联知识点:Hermes smart routing 把 prompt caching 和模型成本一起考虑;Guga context policy 通过稳定前缀和 artifact refs 降低重复输入。
面试官:遇到 429 和配额不足怎么做?第二层追问:所有请求都 fallback 会不会把成本打爆?
我:限流不是无限 fallback,而是资源调度。要有 rate-limit aware scheduler,按 tenant quota、任务优先级、模型池和 provider 配额做 queue、concurrency limit、backoff、budget guard。低优先级任务可以延迟或降级,高风险交互任务才选择性 fallback。fallback 也要受预算和 capability 约束,不是一路换更贵模型把成本打爆。超过上限要给用户透明反馈,比如“当前模型池拥塞,可等待、降级或暂停”,而不是静默失败。
理解与记忆 · 背后工程点
背后工程点:限流不是简单重试,而是资源调度和预算控制。
专业术语:
Backoff:退避重试。
Priority Queue:优先级队列。
Concurrency Limit:并发限制。
Budget Guard:预算保护。
为什么这样回答:这能回答生产流量下的稳定性和成本风险。
小白解析:餐厅爆单时不是所有菜都叫专车送,要按急单、普通单和厨房能力排队。
关联知识点:Hermes credential pool 和 fallback 处理 429/402;Guga runtime 需要把预算和 fallback 写成可审计策略。
面试官:长上下文任务怎么路由?第二层追问:直接选最大窗口模型可以吗?
我:最大窗口不是默认答案。长上下文任务先判断是否真的需要全量原文:能用 retrieval、artifact refs、summary、structured index、compact boundary 解决,就不要把所有内容塞进 prompt。只有必须全局推理、跨文档关系强依赖全文时,再选长上下文模型。路由要比较压缩后质量、fact retention、cost、latency 和 window risk。大窗口会让成本和注意力风险都上升,不是万能保险。先治理上下文,再选择模型。
理解与记忆 · 背后工程点
背后工程点:长上下文路由要先做上下文治理,再做模型选择。
专业术语:
Context Window:上下文窗口。
Retrieval:检索。
Artifact Ref:产物引用。
Fact Retention:关键事实保留。
为什么这样回答:避免把大窗口当成架构捷径,体现成本和质量意识。
小白解析:查一本书不一定要整本背下来,先用目录和索引找到相关页,必要时才通读。
关联知识点:Context 章节强调事件账本、投影和压缩边界;Hermes 元数据会记录 context length 但仍要配合上下文策略。
面试官:模型版本漂移怎么处理?第二层追问:provider 悄悄更新模型导致质量变了怎么办?
我:同名模型不等于行为稳定。生产要尽量 pin 具体 model id 或 dated version,metadata 记录 release、deprecation 和能力变化。每次模型版本变更都跑路由 eval 和 canary;线上 trace 要能按 model_version 聚合,看成功率、成本、tool error、安全回归有没有漂移。发现 drift 时可以 rollback、degrade、提高 guardrail 或更新 prompt。不能因为 provider 还叫同一个模型名,就默认工具调用、推理风格和输出格式都没变。
理解与记忆 · 背后工程点
背后工程点:模型是会变化的外部依赖,要版本化和监控漂移。
专业术语:
Model Pinning:固定具体模型版本。
Model Drift:模型行为漂移。
Canary:小流量灰度。
Deprecation:供应商下线或弃用。
为什么这样回答:这展示供应商依赖治理经验。
小白解析:同一家店换了厨师,菜单名字没变,味道也可能变,所以要试吃再全面上架。
关联知识点:评测章节的 release gate 和 trace 分群可以用来发现模型版本带来的质量、成本和延迟变化。
面试官:预算怎么强制执行?第二层追问:Agent 已经做到一半了,预算快没了怎么办?
我:预算要作为 runtime 状态强制执行,分 per-turn、per-run、per-tenant、per-tool。路由前做 preflight estimate,执行后用 actual usage settlement 扣减。接近上限时触发 replan:压缩上下文、停掉低价值辅助任务、切便宜模型、请求用户确认或缩小目标。但高风险任务不能为了省钱跳过验证,比如代码改完不跑测试。超预算要可恢复地暂停,记录当前状态和剩余选项,而不是静默失败或继续烧钱。
理解与记忆 · 背后工程点
背后工程点:预算是 runtime 状态机的一部分,要能预估、扣减、暂停和恢复。
专业术语:
Budget Envelope:预算包络。
Preflight Estimate:执行前预估。
Usage Settlement:用量结算。
Pause and Resume:暂停和恢复。
为什么这样回答:成本控制要进入交互体验和恢复语义,而不是账单统计。
小白解析:装修做到一半预算不足,要先停下来确认方案,不能偷偷省掉承重墙检查。
关联知识点:Guga strategy 把预算、可恢复性和用户接管纳入 runtime 设计;评测章节也建议看 cost per successful task。
面试官:Model routing MVP 怎么做?第二层追问:第一版别做什么?
我:Model routing MVP 先可解释、可测试,再智能化。第一版做 provider transport、model registry、task class、static policy、usage/cost tracing、basic fallback 和 conformance tests。先不做自动学习路由、复杂实时竞价、全 provider marketplace、凭证池高级策略。重点是先让主推理和辅助任务分开,能解释为什么选这个模型,fallback 为什么发生,能在 eval 里比较效果。等 trace 和评测稳定,再让策略逐步自动化。
理解与记忆 · 背后工程点
背后工程点:路由 MVP 先可解释、可测试,再智能化。
专业术语:
Static Policy:静态策略。
Conformance Test:契约测试。
Usage Trace:用量轨迹。
Marketplace:市场。
为什么这样回答:最后给出落地路径,控制范围。
小白解析:先有清楚派车规则和行程记录,再做智能调度。
关联知识点:Guga 迁移判断把 Transport ABC、主/辅分离、prompt caching 列为必须采用,凭证池和 models.dev 可 Phase 2。
PRINCIPLE我总结的核心范式
模型路由的核心原则是“先统一接口,再记录能力;先减少浪费,再分层模型;先用 eval 校准,再让策略自动化”。不要把路由做成省钱小技巧,它是 Agent runtime 的资源调度和质量控制面。