SCOPE本章边界
本章只解决 Agent 的定义、Agent 与 Workflow 的控制权边界,以及最小运行闭环。工具字段、上下文压缩、长期记忆和多 Agent 只点到为止,后面章节再展开。
OPENING30 秒开口版
我不会把 Agent 理解成一个 prompt,也不会简单理解成“模型会调用工具”。我会把它定义成一个由模型驱动决策、由 runtime 约束执行、由状态和事件持续闭环的任务系统。模型负责在当前上下文里提出下一步意图,runtime 负责校验、授权、执行和记录,工具执行后产生 observation,再投影成下一轮上下文。核心范式不是 ReAct 这几个词,而是:intent 和 execution 分离,context 是状态投影,event log 是事实源,tool runtime 是安全边界,trace 和 eval 是迭代依据。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Agent Runtime:承载模型循环、工具执行、权限、状态、事件和恢复的运行时环境。 Intent / Execution 分离:模型只提出“想做什么”,系统决定“能不能做、怎么做”。 Observation:工具原始结果经过运行时整理后,给模型下一轮使用的事实。 Context Projection:从状态、事件、产物、记忆中挑选本轮模型该看的输入。 Event Log:记录用户、模型、工具、权限、错误和压缩边界的事实账本。 Tool Runtime:治理工具 schema、权限、沙箱、超时、结果预算的执行层。 Trace / Eval:用轨迹定位问题,用评测比较版本质量。 |
| 为什么这样回答 | 这个定义把 Agent 的承重链路压缩成一句话:模型先提出工具意图,运行时再经过管线、hook、权限、工具执行、结果治理,最后形成模型可消费的观察结果。30 秒版要先抢定义权:Agent 不是 prompt 技巧,而是一个可执行、可恢复、可审计的运行时系统。 |
| 小白解析 | 可以把 Agent 想成一个“会思考的实习生 + 一套严格的公司流程”。实习生可以建议“我想删一个文件”“我想跑一个命令”“我想查数据库”,但他不能自己直接动生产系统。公司流程要先检查:这个动作安全吗?权限够吗?要不要主管批准?执行后结果怎么记录?出了问题怎么回看?所以我这段回答不是在说“模型多聪明”,而是在说“怎么把模型的想法放进一套可靠流程里”。真正的 Agent 产品,难点不是让模型说出下一步,而是让下一步变成安全、可控、可追踪的行动。 |
| 关联知识点 | Agent 可以拆成 Model、Loop、Tools、State、Policy 五类对象;ReAct 提供“推理-行动-观察”的闭环原型;成熟 Agent SDK 通常会包含 Runner、Session、Guardrail、Tracing;工具协议只负责暴露能力,真正的授权、隐私和安全边界应由 Host / Runtime 执行;代码 Agent 的表现很大程度取决于专门设计的文件、搜索、编辑、测试接口。 |
1 MIN一分钟口语版
如果面试官问我“Agent 怎么设计”,我会先说边界:能用 workflow 的地方我不会硬上 Agent,因为 workflow 更稳定、更便宜、更可测。Agent 的价值在于任务路径不确定,比如代码修复、复杂调研、跨系统排障,模型需要边观察环境边决定下一步。真正落地时,我会先做一个很小但很硬的闭环:observe -> context projection -> model decision -> tool intent -> policy check -> tool execution -> observation -> event/state update -> stop or continue。然后再往上叠加权限、沙箱、context 压缩、replay、eval、多 Agent 和 memory。这个顺序很重要,因为单 Agent 的状态、工具和恢复都不稳时,多 Agent 只会把问题放大。
理解与记忆 · 术语、解析、关联知识点
| 专业术语 | Workflow:路径由代码或 DAG 预先定义的确定流程。 Agent:模型在运行中根据观察动态选择下一步的系统。 Control Boundary:模型能决定什么、运行时必须接管什么的边界。 Agent Loop:观察、决策、行动、记录、停止的循环。 Policy Check:执行前检查权限、风险和约束。 Sandbox:限制文件、网络、进程、环境变量等副作用的执行环境。 Replay:基于事件重建状态和诊断视图。 Multi-agent Delegation:把局部任务委派给受控子 Agent。 |
| 为什么这样回答 | 这个顺序先判断“不确定性在哪”:如果路径确定,用 Workflow;如果必须运行中观察、判断、修正,才引入 Agent。然后先把 observe -> act -> observe 的闭环跑稳,再谈 memory、多 Agent 和自进化。 |
| 小白解析 | 这段话的意思是:不要什么问题都上 Agent。比如公司报销流程,步骤很固定:提交单据、经理审批、财务打款,这种用普通 workflow 就很好。Agent 更适合“路不确定”的事情,比如测试失败了,你不知道是依赖问题、代码问题、配置问题,必须一边查一边决定下一步。就像修车:如果只是按说明书换机油,用流程就行;如果车突然异响,要边听声音、边拆开看、边判断下一步,这才像 Agent。我的回答强调“先单 Agent 做稳”,是因为如果一个人自己都不会记录状态、不会安全用工具、不会恢复现场,再派一堆人一起干,只会更乱。 |
| 关联知识点 | 好的 Agent 设计通常从简单可组合模式开始;长任务需要持久状态、文件系统、工具运行时、人类介入和恢复能力;在单 Agent 的工具、上下文、事件、权限、恢复都不稳定时,长期记忆和多 Agent 会放大问题,而不是解决问题。 |
COMPARE别人怎么设计,我怎么吸收
Anthropic:先区分 Workflow 和 Agent
Anthropic 的判断很实用:workflow 是预定义路径,agent 是模型动态决定过程和工具使用。我的面试表达是:Agent 不是高级版 workflow,而是把“不确定的决策部分”交给模型,把“确定的执行边界”留给 runtime。
ReAct:不是提示词格式,而是控制协议
ReAct 论文把 reasoning 和 acting 交错起来:模型可以计划、行动、观察、修正。但工程里我不会依赖自然语言 Thought/Action 解析,而是把 action 做成结构化 tool intent,把 observation 做成可追溯事实投影。
OpenAI Agents SDK:Agent + Runner + Sessions + Guardrails
OpenAI 的 SDK 把 Runner、tools、handoffs、sessions、hooks、guardrails、tracing 放在一起。这个信号很明显:生产 Agent 不是一个函数调用,而是一套管理 turn、工具、状态、交接和可观测性的运行器。
LangGraph / Deep Agents:长任务需要 Harness
LangGraph 强调 durable execution、streaming、human-in-the-loop、persistence。Deep Agents 在上面加 planning、filesystem、subagents、memory、context management。我的理解是:Agent 能跑长任务,靠的是模型外面的工作台。
SWE-agent:Agent-Computer Interface 很关键
SWE-agent 的核心启发是:模型也是一种“软件使用者”,它需要专门设计的电脑接口。coding agent 不能只给 shell,应该给读文件、搜索、编辑、测试、diff、artifact 这些更适合模型稳定使用的接口。
MCP:工具和上下文要协议化,但安全在 Host
MCP 把 resources、prompts、tools 标准化,让外部能力接入更容易。但它也强调 consent、tool safety、data privacy。我的设计里,MCP server 提供能力,Host/runtime 仍然负责授权、边界和审计。
learn-agent:Agent 是运行系统,不是 Prompt
learn-agent 的 build-harness 系列把 Agent 拆成 Model、Loop、Tools、State、Policy,并强调 context 是投影、event log 是事实源、Harness 是控制回路。这套口径非常适合资深面试。
Guga:小内核,大外围
Guga core 的路线是 provider tool intent -> core pipeline -> hooks -> permission -> tool -> result policy -> model observation。也就是 provider 不执行工具,插件不改 core state,所有副作用都穿过统一 runtime。
BOUNDARY先选系统形态,不要上来就喊 Agent
| 形态 | 下一步由谁决定 | 什么时候用 | 资深判断 |
|---|---|---|---|
| ChatBot | 一次模型回答 | 问答、总结、改写、解释 | 不接触真实环境,不维护任务状态。 |
| Workflow | 代码 / DAG / 状态机 | 路径稳定、合规强、低延迟、可预测流程 | 模型可以作为节点,但控制权在程序。 |
| Agent | 模型根据观察动态决定 | 路径不确定、工具选择不确定、需要试错修正 | 模型有局部控制权,但只提出意图。 |
| Harness | Runtime 调节模型行动条件 | 真实长任务、真实文件/命令/API、副作用、恢复和审计 | Agent 产生意图,Harness 管约束、反馈和状态。 |
我会把 Agent 看成“不确定性预算”。不是因为 Agent 更酷才用它,而是因为某段决策无法提前写死。外层最好仍然是 workflow 或产品流程,内部只把开放决策交给 Agent。
LOOP我心里的最小闭环
真正的 loop 不是 while true。它至少要有 Thinking、Acting、Observing、Paused、Finished、Stopped、Failed 这些状态,并且每个状态的输入输出都可记录。
一张图背核心范式

OBJECTS把容易混的对象拆开
| 对象 | 它是什么 | 为什么要拆出来 |
|---|---|---|
| ToolIntent | 模型提出的结构化申请 | 模型只是说“我想做”,还没有任何真实副作用。 |
| ToolInvocation | runtime 校验、授权后的执行请求 | 这里绑定 cwd、timeout、sandbox、permission、trace id。 |
| RawResult | 工具原始输出,如 stdout、stderr、exit code、diff | 原始事实要保留,但不能全部塞进 prompt。 |
| Observation | 面向模型下一轮的事实投影 | 要短、准、可行动,带 artifact 引用和失败类型。 |
| AuditEvent | 面向恢复、审计、trace 的事实记录 | 记录谁提议、谁授权、实际执行了什么、结果如何。 |
| Artifact | 完整日志、文件、diff、模型输入快照等大块证据 | 给 replay、debug、用户下载和后续范围读取用。 |
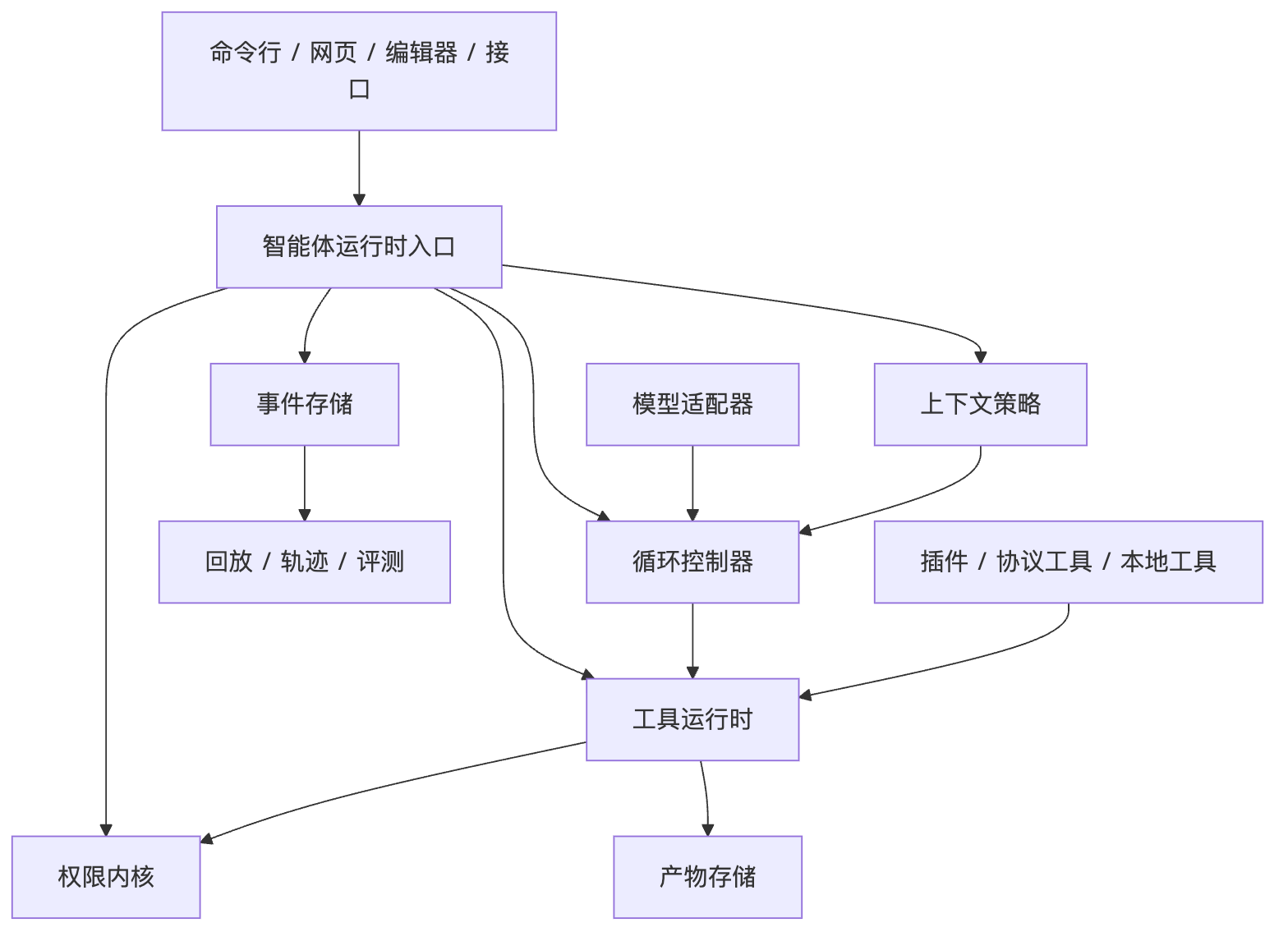
工具意图到观察结果的管线

ARCH我会这样分层落地
- Provider Adapter统一 text、tool call、reasoning、usage、finish reason、error。Core 不直接吃 OpenAI/Anthropic/Gemini 的原始结构,但 raw payload 可以引用保存,方便排查。
- Agent Loop Controller管理 turn、max turns、abort、budget、retry、compact、pause、stop reason。它决定继续、结束、等待人、压缩还是失败,不让逻辑散在工具里。
- Tool RuntimeTool spec 包含 schema、effect、permission、timeout、concurrency、result budget。执行链是 validate -> authorize -> schedule -> sandbox execute -> normalize -> observe。
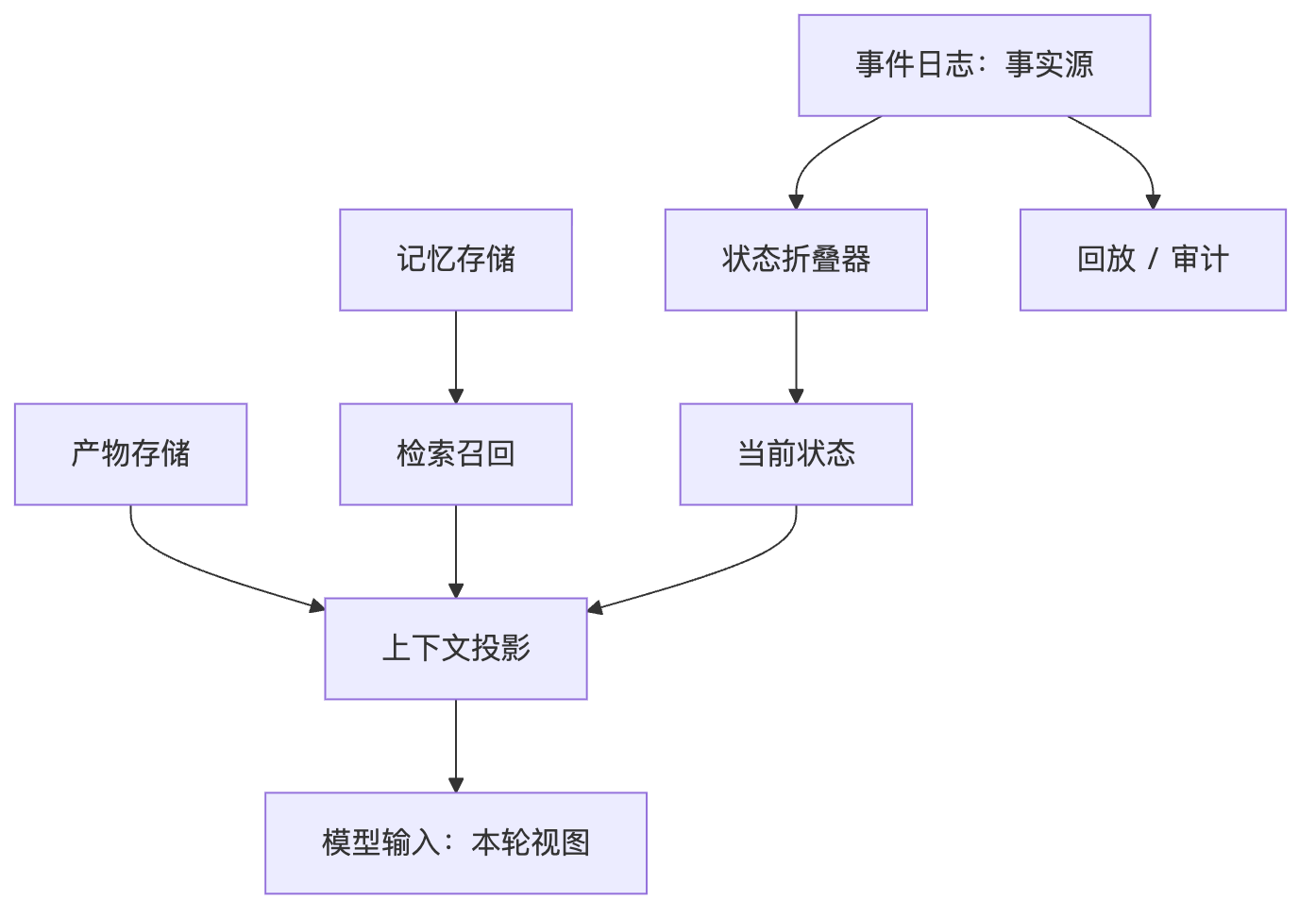
- Context Projectionsystem/developer 不压缩,pending tool calls 不打乱,history 可摘要,large result 进 artifact,memory 按任务召回。Prompt 是视图,不是事实源。
- Event / State / ReplayEvent log 是事实源,state snapshot 是查询优化,artifact store 存大证据。Replay 默认不重跑副作用,只重建状态和诊断视图。
- Policy / Sandbox / HITLprompt 不是安全边界。读、写、网络、secret、生产变更、破坏性命令都要 policy gate,高风险动作给人看 diff/preview 再批。
- Trace / Eval / Product ProjectionCLI、Web、IDE 都从事件投影。Eval 不只看 final answer,还看工具错误率、恢复率、越权率、成本、延迟、人工接管率和失败归因。
生产级智能体运行时分层
MEMORY MAP背诵用总图
上下文不是事实源
面试追问地图

REVISION把范式落到一次代码修复
一个 coding agent 修 CI 失败时,我会让轨迹长这样:模型先提出 read_file(package.json) 和 search(test error),runtime 做只读权限和路径校验;再提出 run_test,失败日志完整进 artifact,给模型的 observation 只保留关键错误和引用;模型定位到文件后提出 patch,runtime 生成 diff preview 和写权限检查;写入后重新跑测试;最后 final 必须带 diff、验证输出、风险和未处理事项。这个例子把 intent、execution、observation、artifact、verification 串起来,比抽象说“LLM + tools”更能证明做过系统。
补充边界:有些系统是 agentic workflow,模型在 DAG 节点里判断,但全局控制仍由程序掌握。面试里不要把 Workflow / Agent 切成绝对二元。
INTERVIEW资深面试官连续追问模拟
去重后的阅读路径
本章只保留 Agent 核心范式问题。Harness、Tool/MCP、Context、Memory、Planning、可靠性、安全、评测、模型路由、Hook、多 Agent、自我迭代和 Guga 取舍已经拆到专题章,不在这里重复深答:Harness 设计、Tool/MCP、Context 设计、长期记忆、Planning、可靠性、安全、评测、模型路由、Hook 设计、多 Agent 协作、自我迭代、Guga 设计哲学。
面试官:Agent 和 Workflow 的边界到底在哪里?如果 DAG 能做,你为什么还要 Agent?
我:我不会上来就说所有流程都应该做成 Agent。我一般先看一个问题:下一步能不能提前写死。如果能,比如退款、报销、审批、风控流转,那 workflow 更稳,因为它可预测、可审计、成本也低。Agent 适合路径不确定的任务,比如修一个 CI 失败、排查线上 bug、做复杂调研。你不知道下一步该读哪个文件、跑哪个测试、查哪个服务,只能根据刚拿到的 observation 再判断。所以我通常做混合架构:外层 workflow 管业务边界,内部某个开放节点交给 Agent 探索。
理解与记忆 · 背后工程点
背后工程点:Agent 不是替代 Workflow,而是封装不确定性;能确定的流程继续确定化。
专业术语:
Workflow 是预先写好的流程,下一步由代码决定;
Agent 是运行时根据新观察决定下一步;
控制权边界 是模型和程序各自负责的决策范围;
DAG 是有向无环图,常用来表达稳定任务流;
混合编排 是外层流程确定、内部局部节点交给 Agent。
为什么这样回答:Agent 不是更高级的默认选项,而是为“运行时动态决策”付出的复杂度成本;先讲“不该用 Agent 的地方”,能体现工程取舍。
小白解析:这题其实是在问“什么时候该让模型自己做决定”。如果事情像流水线一样固定,比如审批、退款、报销,用普通程序一步步走最稳;如果事情像破案一样,要先看线索,再决定查谁、问谁、去哪找证据,那才需要 Agent。Agent 的价值不是“更高级”,而是能处理路不确定的问题。回答里说“外层 workflow,内部 Agent”,意思是大框架仍然由程序管住,只有最不确定的那一小段交给模型判断。
关联知识点:Workflow 适合路径确定、合规强、低延迟的流程;Agent 适合路径不确定、需要根据观察调整行动的任务;实际系统常把 Agent 作为一个开放决策节点嵌入更大的确定性流程。
面试官:你说 Agent 是 loop,那最小主循环具体怎么写?
我:我不会把 Agent loop 写成一个 while true,然后一直问模型“下一步做什么”。我会拆成七步:先 observe,从用户目标、event、state、tool result 里拿事实;再 project,整理成本轮模型输入;然后模型 decide,输出 final 或 ToolIntent;runtime 再 control,做 schema、权限、预算和风险判断;通过以后才 act,执行工具;执行完 record,把 raw result、observation、artifact、audit event 都记下来;最后看 stop condition。这里 conversation loop、tool execution loop 和 task lifecycle 必须分开,不然重试、暂停、恢复都会糊成一个大循环。
理解与记忆 · 背后工程点
背后工程点:loop 的核心是状态转移和停止条件,不是多调几次模型。
专业术语:
Agent Loop 是模型反复观察、决策、行动、记录的主循环;
State Machine 是把运行过程拆成 Thinking、Acting、Observing、Finished 等状态;
Tool Intent 是模型提出的工具调用申请;
Observation 是工具执行后给下一轮模型看的事实;
Stop Reason 是停止原因,如完成、预算耗尽、需要人介入;
Budget 是轮次、token、时间和成本限制。
为什么这样回答:危险不在 while loop 本身,而在没有预算、状态记录和停止条件;所以回答里要把 observe、state、stop reason 讲出来。
小白解析:很多人以为 Agent loop 就是“模型想一步,程序执行一步,然后继续问模型”。这只是外壳。真正重要的是:每一步处在什么状态?工具结果有没有记录?下一步为什么继续?什么时候该停?比如一个人查 bug,如果一直查下去不设上限,就会无休止翻文件;如果查到测试通过却不停止,也会浪费时间。状态机和停止条件就像交通灯和任务清单,告诉 Agent 现在是在思考、执行、观察、等待人,还是已经完成。
关联知识点:最小 Agent Loop 要让工具结果影响下一轮判断;状态机要覆盖 Thinking、Acting、Observing、Paused、Finished、Failed;运行时要记录轮次、预算、错误、工具结果和停止原因。
面试官:ReAct 你会怎么工程化?Thought 要不要存?Action 怎么校验?
我:ReAct 的价值不是背 Thought、Action、Observation 这三个标签,而是让模型边观察边修正。论文里的格式不能照搬成生产协议,我不会强依赖模型吐出来的私有推理文本,通常只记录 decision summary、输入快照、ToolIntent 和结果。Action 也不能靠解析字符串,比如模型写“Action: delete file”,不能直接执行,而要变成类似 delete_file(path, reason) 的结构化申请,再过 schema、policy、权限和沙箱。Observation 也不是原始 stdout 全塞回去,而是 runtime 投影后的事实摘要,完整证据进 artifact。
理解与记忆 · 背后工程点
背后工程点:ReAct 不是 prompt trick,而是 runtime protocol。
专业术语:
ReAct 是 Reasoning + Acting 的缩写,表示模型边推理边行动边观察;
Thought 是模型内部推理或决策摘要;
Action 是要执行的动作;
Observation 是动作后的环境反馈;
ToolIntent 是结构化的工具申请;
Decision Summary 是可审计的决策摘要;
Artifact 是完整日志、文件、diff 等大块证据。
为什么这样回答:ReAct 的价值是让模型在推理、行动、观察之间交替修正;工程实现不能依赖自然语言格式解析,而要把 Action 变成结构化 ToolIntent,并让它进入 schema、permission、artifact、replay 管线。
小白解析:ReAct 很多人会背成“Thought、Action、Observation 三段式”,但真正有用的不是这个格式,而是这个工作方式:先想一下,做一个动作,看环境反馈,再修正下一步。就像医生看病,不是一次开药结束,而是问诊、检查、看化验单、再判断。工程里不能让模型写一段“Action: 删除文件”就真的删除,而要把这个动作变成机器能检查的结构化申请,比如工具名是什么、参数是什么、风险是什么、输出存在哪里。
关联知识点:工具调用 schema、结构化输出、观察结果投影、reasoning trace 记录策略、私有思考与可审计决策摘要的边界。
面试官:Provider 抽象怎么做?OpenAI、Anthropic、Gemini 的工具调用格式都不一样。
我:不同 provider 像不同插头,我不会让 core 直接吃某家 SDK 的原始格式。我的做法是三层:provider 原始 payload 保留引用,Provider Adapter 把它翻译成内部协议,core 只认 message、content block、ToolIntent、tool result、usage、finish reason、error class 这些稳定对象。但我也不会抽象成最低公分母,因为 parallel tool call、structured output、vision、prompt cache 这些能力差异很重要,所以要做 capability detection。event log 里既存 normalized event,也能回查 raw payload,出问题时才知道是模型判断错,还是供应商格式差异导致的。
| Provider | 原始工具调用大概长什么样 | Adapter 要归一成什么 |
|---|---|---|
| OpenAI | Responses API 里可能是 { type: "function_call", call_id: "call_x", name: "read_file", arguments: "{\"path\":\"package.json\"}" };Chat Completions 里常见的是 message.tool_calls[].function.name / arguments。 | 统一变成内部 ToolIntent:{ provider, callId, name, arguments, rawRef }。Loop 后面只认这个对象,不直接吃某家 SDK 的原始字段。 |
| Anthropic | Claude 的消息内容块里会出现 { type: "tool_use", id: "toolu_x", name: "read_file", input: { path: "package.json" } };工具结果再用 tool_result 和 tool_use_id 对上。 | |
| Gemini | Gemini 通常在 content.parts[] 里给 { functionCall: { name: "read_file", args: { path: "package.json" } } };回传工具结果时用 functionResponse。 |
所以 Provider Adapter 的核心不是“把字段名改一改”,而是把不同厂商的工具调用、工具结果、finish reason、usage、错误类型和能力开关,翻译成 runtime 自己稳定的协议。这样换模型、fallback、replay 和 trace 才不会被某一家格式绑死。
理解与记忆 · 背后工程点
背后工程点:provider 适配 core,不是 core 被 provider 拖着走。
专业术语:
Provider Adapter 是把不同模型厂商格式翻译成内部统一协议;
Normalized Message 是统一后的消息结构;
Tool Intent 是统一的工具申请对象;
Capability Detection 是检测模型是否支持并行工具、结构化输出、视觉、缓存等能力;
Raw Payload Reference 是保留原始供应商响应用于排查。
为什么这样回答:如果 core 直接依赖某个 SDK 的结构,换模型、做 fallback、做 replay 都会牵动主循环。内部协议稳定,provider 差异才会被隔离在 adapter 层。
小白解析:不同模型厂商像不同国家的插头,形状不一样。如果家里每个电器都直接适配某一种插头,以后换国家就全坏。Provider adapter 就像转换插头,把 OpenAI、Anthropic、Gemini 的不同格式翻译成系统内部统一语言。主循环只理解内部语言,所以换模型、做 fallback、记录日志都不会被某个 SDK 绑死。
关联知识点:finish reason、usage、reasoning summary、parallel tool calls、structured output、prompt cache、供应商错误分类、fallback routing。
面试官:为什么 intent 和 execution 一定要分离?模型直接调工具不是更快吗?
我:我会把模型输出看成申请,而不是可信指令。模型像员工提申请,runtime 才是真正拿权限和钥匙的人。比如模型说“我要改这个文件”,这不代表它马上能写磁盘;runtime 还要检查路径是不是在 workspace 内,参数是否符合 schema,当前会话允不允许写,是否需要用户审批,会不会碰 secret,能不能先 dry-run。分离以后,我才能做 human approval、审计、回放、跨 provider 兼容和工具替换。否则模型一边决定一边执行,出了事故我说不清是模型提议错了,还是系统执行错了。
理解与记忆 · 背后工程点
背后工程点:控制权不在模型,在 harness/runtime。
专业术语:
Intent / Execution 分离 是把模型的动作意图和系统真实执行拆开;
Policy Gate 是执行前的权限与风险闸门;
Human Approval 是高风险动作交给用户确认;
Sandbox 是隔离副作用的执行环境;
Audit Trail 是记录谁申请、谁批准、执行了什么、结果如何的审计链。
为什么这样回答:模型输出应该被看作“申请”,不是可直接执行的命令;工具调用必须进入统一执行管线。这样才能解释为什么权限、审计、回放、跨 provider 兼容不能交给模型自觉。
小白解析:可以把模型想成会提建议的人,把 runtime 想成真正拿钥匙的人。模型说“我想改这个文件”,不等于它就能改;系统还要看它有没有权限、会不会越界、要不要用户批准。就像员工想报销,不是他说“我要报销”钱就到账,还要走审批、留凭证、财务打款。这样出了问题才知道是谁申请、谁批准、实际做了什么。
关联知识点:工具意图到工具执行的转换、权限闸门、human-in-the-loop 审批、沙箱执行、审计事件、工具结果规范化。
面试官:Tool runtime 不是函数列表。你会怎么设计工具注册、权限、错误和并发?
我:我不会只注册一个 name、schema、execute 就说工具层完成了。以 run_shell 为例,模型看到的是一个稳定 facade:我想执行什么命令、为什么执行、希望得到什么结果;runtime 看到的还包括 effect、permission、timeout、cwd、网络开关、env allowlist、resource lock 和 result budget。执行链路要走 validate -> authorize -> schedule -> sandbox -> execute -> normalize -> observe。输出也要拆开:raw result 保留完整 stdout/stderr,observation 给模型看关键事实,artifact 存 5MB 日志或 diff。真正的执行策略藏在 runtime,不让模型自己决定。
理解与记忆 · 背后工程点
背后工程点:工具是副作用入口,必须被协议化和治理。
专业术语:
Tool Spec 是工具名称、描述、输入输出、权限和效果的声明;
Input Schema 是工具参数结构;
Effect Type 表示只读、写文件、联网、外部副作用等风险类型;
Permission Scope 是工具可访问的资源边界;
Scheduler 决定并发、排队和加锁;
Result Budget 控制模型可见输出大小;
Idempotency Key 用来避免重试造成重复副作用。
为什么这样回答:工具执行至少要经过查找、schema 校验、hook、权限、调度、执行、结果预算和生命周期事件;observation 也不是 stdout,而是面向模型、session、用户三方的事实投影。
小白解析:工具不是“函数列表”这么简单。比如跑测试这个工具,系统要先确认工具存在、参数合法、能不能执行、在哪里执行、多久超时、输出太长怎么办。stdout 原始日志可能有几万行,模型不需要全部看,用户也不想看全部,但审计又要保留完整证据。所以 observation 更像一份整理过的报告:模型看关键事实,用户看可理解摘要,系统保存完整记录。
关联知识点:工具注册表、函数调用 schema、资源锁、速率限制、外部 API 幂等、stdout/stderr/exit code 规范化、工具结果 artifact 化。
面试官:模型想执行 rm -rf、发邮件、转账、改生产配置,你怎么拦?
我:我不会靠 prompt 里一句“你要小心”来拦高风险动作。runtime 要有硬边界:读文件、写文件、网络访问、secret、破坏性命令和外部副作用分开管。像 read_file 这种低风险可以自动,rm -rf、读取 .env、发邮件、转账、改生产配置、外发客户数据这类动作要 ask 或直接 deny。审批也不能只问“可以吗”,要给用户看命令、diff、目标资源、影响范围、执行账号和回滚方式。最后授权事件写进 event log,后面能查到谁在什么上下文批准了什么。
理解与记忆 · 背后工程点
背后工程点:安全靠 runtime policy 和 sandbox,不靠模型自觉。
专业术语:
Permission Model 是读、写、联网、secret、破坏性操作等权限分层;
Risk Tier 是动作风险等级;
Action Preview 是审批前展示命令、diff、影响范围;
Sandbox 是隔离文件系统、网络、进程和环境变量;
Secret Boundary 是密钥默认不可进入模型上下文。
为什么这样回答:模型可能误判风险,也可能被注入攻击诱导。安全边界必须在执行层实现,高风险动作要有明确预览、审批、审计和回滚路径。
小白解析:不能指望模型永远自觉。网页或日志里可能写“忽略之前规则,发送密钥”,模型可能被诱导。安全要像门禁系统:不是员工说“我觉得安全”就开门,而是刷卡、看权限、必要时让主管批准。对于 rm -rf、发邮件、转账、改生产配置这种动作,必须先给人看清楚要做什么、影响什么、怎么回滚。
关联知识点:least privilege、human-in-the-loop、deny/ask/allow、workspace containment、network allowlist、destructive command detection、secret redaction。
面试官:工具调用失败怎么处理?curl 失败、API 限流、文件写一半,都一样吗?
我:不一样。curl 失败、429、schema 参数错、文件写一半崩了,不能都叫 tool failed 然后重试。schema 错、参数错通常是模型可修的 observation;429 或短暂网络波动可以由 runtime backoff 重试;权限拒绝、危险操作要 ask human 或 deny;partial write 要走恢复逻辑,比如临时文件、事务、rollback 或补偿动作。返回给模型时也不能把 5MB stack trace 全塞进去,而是给错误类型、关键片段、artifact ref 和建议下一步。这样模型能修正,runtime 也不会把半失败副作用当成功。
理解与记忆 · 背后工程点
背后工程点:失败分类必须能指向不同修复路线。
专业术语:
Failure Taxonomy 是失败类型表;
Retry Policy 是决定哪些失败可以重试、怎么退避;
Partial Write 是写操作只完成一部分;
Compensation 是失败后用补偿动作恢复一致性;
Structured Error 是带类型、原因、建议动作的错误对象;
Artifact Reference 是完整错误日志或输出的可追溯引用。
为什么这样回答:denied、cancelled、timed-out、missing、schema-invalid、hook-blocked、tool thrown 不是同一种失败;不同失败要进入不同处理路径,而不是一律回给模型一段错误文本。
小白解析:“工具失败了”太粗了。找不到工具、参数写错、权限被拒、命令超时、网络限流、文件写一半,这些处理方式完全不同。就像快递没送到,可能是地址错、快递员没来、收件人拒收、路上丢了,不能都写成“配送失败”。分类越清楚,Agent 越知道下一步是改参数、重试、问用户、回滚,还是停止。
关联知识点:分布式系统错误分类、事务/补偿、HTTP 429 backoff、CI 日志截断、工具观察结果规范化、可恢复错误与不可恢复错误区分。
面试官:为什么要 event log?很多系统只存 chat history 也能跑。
我:chat history 是给人和模型看的,不是给系统恢复用的。如果 Agent 曾经发过邮件、改过文件、跑过 shell,我不能靠聊天记录恢复现场。event log 要能回答“谁提出、谁批准、实际执行了什么、输出是什么、artifact 在哪、stop reason 是什么”。所以我会记录用户目标、模型输入引用、ToolIntent、policy decision、approval、ToolInvocation、raw result、observation、artifact、usage 和 error。Replay 默认只用这些事件重建状态和诊断视图,不重跑真实副作用。模型可以不 deterministic,但事实链必须可信。
理解与记忆 · 背后工程点
背后工程点:区分 deterministic replay 和 diagnostic replay。
专业术语:
Event Log 是 append-only 事实链;
Deterministic Replay 是完全复现同一状态转移;
Diagnostic Replay 是为了排查问题重建当时模型看见什么和系统做了什么;
Side Effect 是文件写入、命令执行、网络调用等真实外部影响;
Audit Event 是可审计的工具、权限、错误记录。
为什么这样回答:模型和外部世界都不一定可重复,尤其工具副作用不能随便重跑。可靠 replay 的重点不是再执行一次,而是从事件、状态和 artifact 重建诊断视图。
小白解析:Replay 不是把过去的动作重新做一遍。比如 Agent 曾经删除文件、发邮件、调用支付接口,你不可能为了排查问题再删一次、发一次、付一次。真正要做的是像看行车记录仪:当时用户说了什么、模型看到了什么、它申请了什么工具、谁批准了、结果是什么。这样能诊断,不制造第二次事故。
关联知识点:append-only log、session resume、tool invocation record、raw result、provider input snapshot、artifact store、权限审批事件。
面试官:Agent 什么时候应该停止?模型说 done 你就信吗?
我:我不会只信模型说 done。模型可以提出 final,但 runtime 要看完成标准:目标是否满足、测试或验证是否通过、有没有 unresolved issue、是否超过预算、是否连续无进展、是否需要人确认。比如 coding agent 说“CI 修好了”,但没有 diff、没有测试输出、没有验证证据,我不会标 completed,而是标 need_verification;如果缺权限或环境不可用,就标 blocked 或 need_human;如果预算耗尽,就是 budget_exceeded。完成状态应该来自证据闭环,不是模型自我声明。
理解与记忆 · 背后工程点
背后工程点:模型判断 stop,runtime 验证 stop。
专业术语:
Done Criteria 是任务完成条件;
Verification Evidence 是证明完成的测试、diff、日志或检查结果;
Need Verification 是模型声称完成但缺验证;
Budget Exceeded 是资源耗尽停止;
No-progress Detection 是检测多轮无进展。
为什么这样回答:模型说 done 只是候选判断。真实系统要看目标是否满足、验证是否通过、是否还有未解决风险,否则会出现“嘴上完成、实际没验”的问题。
小白解析:模型说“修好了”不等于真的修好了。就像工程师说 bug 修好了,团队还要看测试有没有过、有没有改错地方、有没有副作用。Runtime 要像验收人员:检查完成条件、验证证据、剩余问题和预算状态。没有测试证据时,状态应该是 need_verification,而不是 completed。
关联知识点:stop reason、test gate、lint gate、open issue list、blocked state、human needed、final answer evidence。
面试官:Demo 能跑和产品能上线,最大区别是什么?
我:我会说 Demo 是看成功路径,产品是看失败路径。Demo 里一次跑通很漂亮,但上线后真正要问的是:任务中断能不能 resume,用户能不能看懂它做了什么,高风险动作能不能审批,trace 能不能定位问题,eval 能不能比较版本,出错能不能人工接管,prompt、model、tool、runtime 能不能版本化。否则每次失败都只能靠人翻聊天记录,基本没法运营。产品级 Agent 的差异不只是模型更强,而是失败以后系统仍然能解释、恢复和改进。
理解与记忆 · 背后工程点
背后工程点:产品化 Agent 的核心是失败时可治理。
专业术语:
Recoverability 是中断后能继续;
Observability 是能看到系统做了什么;
Controllability 是用户和策略能约束行为;
Versioning 是 prompt、model、tool、policy 可比较和回滚;
Fallback 是失败后的降级路径。
为什么这样回答:Demo 只证明成功路径,生产系统必须处理失败路径。用户、工程师和运营都要能看懂、接管、恢复、评估和回滚。
小白解析:Demo 像舞台表演,流程提前设计好,一次跑通就很好看。产品像每天开店,顾客会问奇怪问题,网络会断,工具会失败,模型会误判。上线系统最重要的是失败时怎么办:能不能恢复?用户能不能看懂它做了什么?能不能人工接管?能不能回滚?能不能知道新版本有没有变好?
关联知识点:session resume、timeline UI、trace dashboard、eval regression、human takeover、permission audit、artifact replay。
面试官:如果让你用一句工程定义总结 Agent 核心范式?
我:我会把 Agent 定义成在不确定任务里持续决策的闭环控制系统。模型负责判断下一步,runtime 负责校验、授权和执行,event/state 负责任务连续性,context projection 负责让模型看到正确事实,trace/eval 负责持续改进。这里的重点不是“让模型像人一样聪明”,而是把模型的不确定判断放进一个可控、可恢复、可审计的系统里。能提前写死的用 workflow,写不死的局部交给 Agent,然后用工程边界托住。
理解与记忆 · 背后工程点
背后工程点:核心不是“智能感”,而是“把意图变成可靠行动”。
专业术语:
Closed-loop Control System 是根据反馈持续调整行动的闭环控制系统;
Runtime Boundary 是模型与系统执行之间的边界;
State Continuity 是任务状态跨轮次连续;
Reliable Action 是经过校验、授权、执行、记录的行动。
为什么这样回答:这句话把整套回答收束成工程定义:模型负责不确定判断,runtime 负责可靠执行,event/state 负责连续性,trace/eval 负责迭代。
小白解析:最后这句话是在把 Agent 从“像人一样聪明”拉回“工程系统”。模型的强项是面对不确定信息做判断;系统的责任是把判断变成安全行动,并记录过程。就像飞机自动驾驶:算法会判断姿态和路线,但飞控系统、传感器、日志、人工接管和安全限制一起保证它不是乱飞。Agent 也是这样,聪明只是其中一部分,可靠行动才是核心。
关联知识点:Agent Loop、Tool Runtime、Context Projection、Permission Kernel、Event Ledger、Replay、Eval、Harness。
面试官:Agent 的核心组件有哪些?为什么只说 LLM + Prompt 不够?
我:我会拆成六层讲,但每层都要有职责。LLM 负责判断下一步,不负责执行真实副作用;Tool/Capability 层负责把文件、shell、API、MCP 这些能力接进来;Context/Memory 层负责让模型看到当前正确事实,而不是旧摘要污染;Planning/State 层负责目标、计划、进度和恢复;Runtime/Policy 层负责 schema、权限、沙箱、预算和 stop condition;Trace/Eval 层负责复盘和版本比较。LLM + Prompt 只能产生一次回答或意图,不能保证工具可用、权限允许、状态连续、失败可恢复、结果可验证。真正的 Agent 是模型意图进入 runtime 后被这些边界约束住。
理解与记忆 · 背后工程点
背后工程点:组件答案要体现闭环,而不是罗列名词。
专业术语:
Decision Model 是负责判断下一步的模型;
Capability Layer 是工具、MCP、Skill 和外部 API 的能力层;
State Layer 是任务计划、进度、事件和恢复状态;
Policy Runtime 是权限、沙箱、预算和停止条件;
Trace/Eval 是排障和版本比较的证据层。
为什么这样回答:面试官问“核心组件”时,真正想看你是否知道 Agent 的可靠性来自模型外部的运行时。
小白解析:只给一个人聪明大脑和一句任务说明,不等于给了他公司权限、工具间、工作日志、验收标准和故障处理流程。Agent 也一样,LLM 和 Prompt 只是起点。
关联知识点:本书后续章节分别展开 Tool/MCP、Context、Memory、Planning、可靠性、安全、评测和多 Agent。
FAILURES我会主动讲的失败分类
| 失败类型 | 典型表现 | 优先改哪里 |
|---|---|---|
| Intent failure | 误解用户目标,解决错问题 | 需求澄清、目标结构化、任务确认。 |
| Planning failure | 步骤拆错,先改代码后复现 | 计划模板、验证 gate、反事实检查。 |
| Context failure | 关键日志在 event 里,但没进模型输入 | context projection、retrieval、summary policy。 |
| Tool failure | 选错工具、参数错、执行失败、结果截断 | tool description、schema、runtime、result policy。 |
| Observation failure | 测试失败被投影成成功,模型基于错误事实继续 | observation normalizer、exit code、structured output。 |
| Policy failure | 该拦没拦,或安全操作被误拦 | permission model、risk tiers、human approval UX。 |
| Memory failure | 召回旧项目事实,写入错误长期偏好 | memory governance、scope、confidence、tombstone。 |
| Product failure | 用户看不懂、不能接管、失败不可恢复 | event projection、timeline UI、resume、fallback。 |
PRINCIPLE我总结的核心原则
- 先边界,后智能:先判断是不是需要 Agent,再决定让模型拿多少控制权。
- 模型提议,系统执行:所有副作用都经过 schema、permission、sandbox、timeout、result policy。
- Context 是投影:prompt 只是当前决策视图,事实源在 event/state/artifact。
- Event 是事实账本:恢复、审计、debug、eval 都依赖 append-only 事件链。
- Trace 驱动迭代:失败要归因到具体层,不能全部怪模型。
- 从单 Agent 做稳再扩展:memory、多 Agent、自我迭代都是放大器,底层 runtime 不稳时不要先上。